| �� |
�˹�����Խ��Խ����,����"����"�ܸ���"����"�� |
|
��
2018��7��9��
����
ת��
�����༭��
|
|
�������ı�ǩ���˹�����,���������,�ڴ� |
����ԭ ��Ŀ���˹�����Խ��Խ�ϻۣ������ġ����ܡ��ܸ��ϡ���������
������������������ ���������ͳɳ���������������ļ�����Ҫ����Ӧ��Ӳ������Ҳ �̲��ݻ� ��
�������ѧϰ���˹�����(AI)�����չ��ǰ����� ���� ��������� ��Դ�������������һϵ�л���ѧϰ�㷨���������ھ���������Ѱ��ijЩģʽ ��ͨ����Щ��������磬�����������Ӿ� ���������õ��˴����չ��������Ϊ ���ļ����������һЩ�ض� ʹ���� չʾ�� ��������� ���� ��
 ���洢���Ķ�ά���� ��
��Դ��IBM̽��Ժ
���洢���Ķ�ά���� ��
��Դ��IBM̽��Ժ������˿����AlphaGo���ϵõ��� ��������� չʾ ���������DeepMind�Ŷӿ����ij���2016��3����һ��5�غϵ� �����л�����Χ������ھ������h���ȷ�Ϊ4��1 �����ڣ�AlphaGoΨһ�Ķ���ֻʣ�� �����ĸ����� ��2017��10�£�DeepMind�Ŷӹ�����һ�� �����汾����AlphaGo Zero������ ������ǿ��ѧϰ������ֻͨ���Լ����Լ����Ľ���ѵ�� ����AlphaGo�� ������ �����ڶ�����רҵ�����������߷��ķǼලʽѧϰ �� �����AlphaGo Zero��100�غ�ȫʤ��ս��սʤ�˻��ܹ������h��AlphaGo ��
������������� ������������ֻ��ġ���ͻ�����νӵġ���Ԫ�� �����ô��������Լ� ָ�� ʹ������ȷ�𰸽���ѵ������Ԫ�м��νӵ�ǿ�Ȼ���˵Ȩ�صõ���ͣ������ֱ�����ϲ����������ȷ�� ��� �� ʵ��ѵ������������ѵ���еõ����ν�Ȩ���ٱ� ���õ�ո�������С�����һ������Ϊ�ж� ��
������������������ ˳���ȵ������㷨������ܹ��� �ռ���Ҳ��������ȡ�������ݱ���������㣬�Լ������ܼ���� ������չ ��Ŀǰ���߱�һ�����㾫�ȵ������������������൱�� ��ʷ߮��� �����ڡ���Ȼ-����ѧ���Ϸ�����һƪPerspective����(https��//go.nature.com/2lWHPww)������������ָ�����������������������ٵ��� ��ս�������ǵ����DZ� �����ڿռ�͵�����������ֻ��Լ��������ܴ����������� ��ʩ��Ƕ��ʽ��Ʒʱ ��
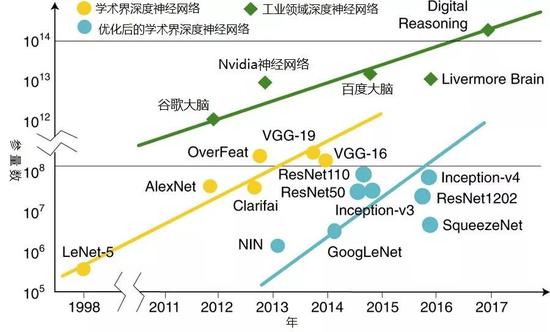 ͼ1��ǰ�����������ĵ��� �����������IJ���������ָ��ʽ���� ��Y��Ϊ�������� ��
ͼ1��ǰ�����������ĵ��� �����������IJ���������ָ��ʽ���� ��Y��Ϊ�������� ��������������ʥĸ��ѧ�����ݴ�ѧ��ɼ����У���й����пƼ���ѧ��̽���Ŷ� ���������������ľ��Ⱥ�ģ��������ݣ��Լ���ͬӲ��ƽ̨���������� ������ָ������������� ������ ��ʩ���ж�(��Ƕ��ʽƽ̨��ִ�е��ж�)�ĵ����ٶȺ�CMOS�����ĵ����ٶȴ��ڲ�ࡪ������������������ ��������������ø���ȷ�����ǵij߶�(��������������������)�� ���� ��
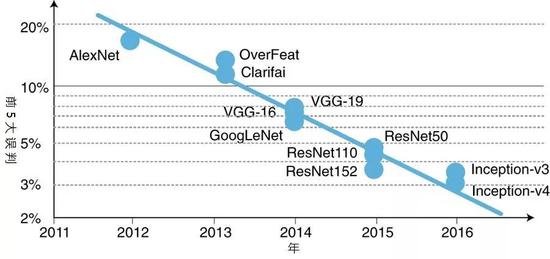 ����ͼ2��ImageNetͼ�����
��������������������ǰ5�����б��� ��ǰ5�����еı�����
�����ָ��ʽ
���� ��Y���������� ��
����ͼ2��ImageNetͼ�����
��������������������ǰ5�����б��� ��ǰ5�����еı�����
�����ָ��ʽ
���� ��Y��Ϊ�������� ������Ȼ��������ʷ߮��� �������������͵�Ӳ��ƽ̨����ͼ�� �����Ԫ(GPU)���ֳ��ɱ��������(FPGA)�Լ�ר�ü��ɵ�·(ASIC)������������ܵ� ����������ǰ�����������������Ҫ �� ���Ƶģ�������Щ�����Ӳ��ƽ̨�Ĵ洢������Ҳ����������߶ȵ����� ��
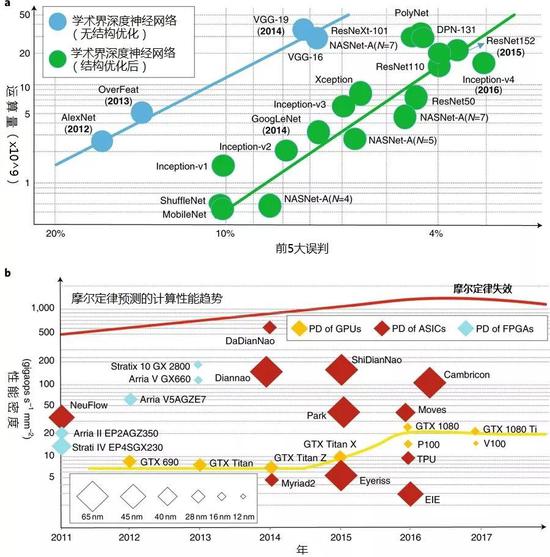 ����ͼ3���������������ܶ��м�IJ�� ��a�� ����������ImageNetͼ�����
���������ȵ�����������ǰ5�����б��� ��b�� ���ȵ�GPU��ASIC��FPGAӲ��ƽ̨�����ܶ� ��Ϊƥ��������������
��������оƬ����������� ������ֻ��ʾ�˶�ڵ���������� ��Y��Ϊ�������� ��
����ͼ3���������������ܶ��м�IJ�� ��a�� ����������ImageNetͼ�����
���������ȵ�����������ǰ5�����б��� ��b�� ���ȵ�GPU��ASIC��FPGAӲ��ƽ̨�����ܶ� ��Ϊƥ��������������
��������оƬ����������� ������ֻ��ʾ�˶�ڵ���������� ��Y��Ϊ�������� ������ʷ߮��� ����ָ������CMOS�����ĵ����������������ļ���ǿ�Ⱥ��ķ������Ҫ��û���ṩ�㹻�� ֧�ţ� �����Ҫ�ڼܹ�����·�������ϼ��Դ��� �������ڴˣ����� ���� ������ ���ϲ�ͬ�ܹ����㷨������ �����������Ŀ����� ��
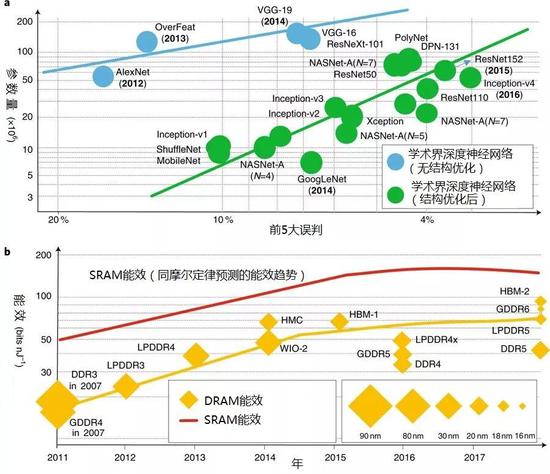 ����ͼ4���ڴ�
�ݷ������ڴ���Ч�м���ڲ�� ��a�� ������(���ڴ�
�ݷ����߶�
�й�)���ո���ImageNetͼ�����
���������ȵ�����������ǰ5�����б��� ��b�� �����洢�������ڴ���Ч ���ڴ���Ч����������
�����½�
����
֧�������������ڴ�
�ݷ��� ������ֻ��ʾ�˶�ڵ���������� ��Y��Ϊ�������� ��
����ͼ4���ڴ�
�ݷ������ڴ���Ч�м���ڲ�� ��a�� ������(���ڴ�
�ݷ����߶�
�й�)���ո���ImageNetͼ�����
���������ȵ�����������ǰ5�����б��� ��b�� �����洢�������ڴ���Ч ���ڴ���Ч����������
�����½�
����
֧�������������ڴ�
�ݷ��� ������ֻ��ʾ�˶�ڵ���������� ��Y��Ϊ�������� ������һ�� ģʽ��������ͳ�ģ����洢��Ԫ�ͼ��㵥Ԫ������ ��ɢ�ķ롤ŵ��������ܹ��� �ȷ���������ʽ�洢��(��������) ���Լ����ڼ��������ڴ洢 ����������Ӧ�� ���� �����Ǹ����⣬ ��Լ���������辫�� ��
�����ڱ��ڡ���Ȼ-����ѧ������һƪ������(https��//go.nature.com/2IZ9VAq)������������IBM̽��Ժ����������������ѧԺ��Manuel Le Gallo���� ���±������ۺ����õ���ʽ�洢�����ڴ��������Լ���ͳ�������㣬�����ܽ��������� ��������ڴ������㵥Ԫ��������˵��һ�����洢���Ķ�ά���У����dz�����Ҫ�ļ��� ʹ��������ͳ���㵥Ԫ����� �������㾫�� ��
����Le Gallo���� ����ͨ���������Է����飬 չʾ�����������dz�Ϊ����Ͼ����ڴ������㡱 ���������� ������ ����֮ǰҲ������ѵ����������� ��
����ΪAI ���ÿ���ר��������оƬ�Ľ�չǰ��Ҳ������оƬ������˾����Ȥ ��������Щʱ�ݡ�ŦԼʱ����������Ŀǰ������45�ҳ�����˾�ڿ�������оƬ��������Ͷ������һ����оƬ������˾�е�Ͷ�ʳ���15����Ԫ�� ����������ǰͶ����������� ��
�������ּ����� ����С�ѧ����Ͳ�ҵ���̽����Ա������Ӧ����ѧϰ��AI��Ӳ������� ��ս�����Լ���֮������ ���� ��