DeepSeek�ƾ�AI����Щϣ��֮�ż����ı����� |
|
�齭·����
��
2025��2��17��
����
ת��
��DNF�������
|
|
�������ı�ǩ��AI |
DeepSeek �ܹ� ͦ����AI��̨�����룬��ֻ�������ڴ�����ģ��(LLM)���� ��õ� ���ƣ�������ΪAI������ ָ��֮�ţ�����Ҳ���������������� ��
ƾ����һϵ�д�ģ�ͣ�DeepSeek ������AI��ģ�ͽ�չ�Ĵ�ͳ��ʽ���� ʹ�ø߰���GPU�� ���Ѵ�����������Դ��ͨ��ѵ�������ģ�ͣ���ȡAI���ܵ��������� ����DeepSeek R1�������辶������ǿ��ѧϰ��������������ģ������ʵ�� ���� �� ����AI�ľ������ٵ���ȡ�����ʽ�Ͷ�룬���Ǹ� ���ӳɱ�Ч�棬������AI�µĽ�չ���� ��
DeepSeek�������������ģ���� ����ģ�����ӵ�Ψһ ������С��ģ��������ģ��Ҳ���г��� ���֣�Ϊ��ҵ�ṩ���ܸ��ŵ� ȡ�� ��
DeepSeek�� ˳��Ҳ������ ���� ������õ�ģ�ͽ��ǿ�Դ�ģ��Կͻ���AI�����߶������ģ�������ʵ��AI�Ĵ��ڻ� ������������ҵ����DeepSeek��ģ�ͣ���������DeepSeek R1�ȿ�Դģ��ȡ��OpenAI�ȸ߰��� �رմ�ģ�� ��
����������ͳ�����ն��ԣ�DeepSeek�ĸ��ֲ��� ҪЮ������һ���� ˶�Ļ��ᣬΪ�����ߡ�ģ��������ģ��ѵ����ģ��С�ͻ���AI ���õ��������Ļ��� �� ������AI�������ܲ��ٽ����ǡ�˭�и����Ǯ��˭����ѵ����ǿ��ģ�͡������ǡ�˭���ø��ٵ�Ǯ���ﵽ ��ͬ�������õ� ������ ��
1.�ǻ���ԭ��������ҵ��������DeepSeek��Դ��ģ
ǧǧ����� ���ö���DeepSeekΪ�������ɴ˹�������̬������AI��ҵ��� ��
��Դ����Դ������Web������ṩ�� �ܹ����� ���ĺ���һ�� ɢ�� ����OpenAI�Ⱦ������ֵĴ�ģ�Ͳ�ͬ��DeepSeek��ģ���ǿ�Դ�ģ�����DeepSeek R1��MIT�����¿�Դ ʹ�� ��
DeepSeek��Դ �ص�͵ͼ���Ҫ��������˳ɱ����ӿ���AI�IJ��� �������� �ܹ���Web��iPhone/iPad��Android���Ƽ��㡢��������������� ���DeepSeek ���� ���Ʒ����� �ܹ���ѽ��룬���� �ܹ��Ƴ��Լ���AI��ģ�ͷ��� ��
��Դģ�Ͳ�����Ӳ�����������Ǻӣ�������Աʮ����������DeepSeek R1�ȿ�Դģ��ȡ��OpenAI�߰��� �ر�ģ�� ��
��DeepSeek ׳������˹�����ģ�Ͳ�ֻ�����й��� �ɹ���Ҳ��Databricks��Mistral��Hugging Face�ȿ�Դ������ �ɹ� ������Դ�˹����ܡ�����ֻ����һ������ҵ̽�� ������������OpenAI GPT�� �ر�ģ�͵Ŀ��С��� ����� ���� ������ ��
DeepSeekѸ�ٳ�Ϊ ������������� ���� ��GartnerԤ�⣬��2026�꣬����80%����ҵ�� ʹ��GenAI����GenAI ���� ����֯ͬʱ�������ٸ�ģ�ͣ���������Ϊ����� ʹ�ð��� ȡ�����ģ�͵�ѹ�� ���� ȡ����ȷ��AIģ�Ͳ� ��ݲ������ ����г�����������Ҫ ��
�ڲ�ͬƽ̨�ϣ�DeepSeek�������� ��� ���ƣ��������������������� ����ƻ����App Store�ϣ�DeepSeekȡ���˾�������OpenAI����Ϊ������������� ���ó��� ������һ���ƶ� �����̵�Google Play�У���1��28������DeepSeek���������� ά�����ȣ��ڶ̶�18����������ﵽ��1600��Σ� ������OpenAI ChatGPT�չ���ʱ900��������������� ��
����AIģ�͵� ֧���߶�DeepSeek ��� �ȳ� ������DeepSeek-V3��R1��700���ģ��������AI����ƽ̨HuggingFace���ṩ�����س�����500��� ��
QuestMobile������ʾ��DeepSeek��2��1�� ����3000���أ���Ϊʷ���������һ��̱��� ���� ��
�ڹ��⣬����Ӣΰ���������ѷ���ڵĶ��������˾�� ���Ȳ���DeepSeek-R1ģ�ͣ�Ϊ�������ṩ���� ��
�����罫DeepSeek-R1ģ�ͱ�������ƽ̨Azure AI Foundry��GitHub��ģ��Ŀ¼�������߽� �ܹ���Copilot +PC ��ƭ������DeepSeek-R1����ģ�ͣ��Լ���Windows�� ����GPU��̬ϵͳ������ ��
�������ѷ�ƿƼ�AWSҲ ���棬������ �ܹ���Amazon Bedrock��Amazon SageMaker AI����AI����ƽ̨�ϲ��� ���� ׳�ɱ�Ч��ߡ���DeepSeek-R1ģ�� ��
Ӣΰ��1��30�� ���棬DeepSeek-R1ģ�Ϳ���ΪNVIDIA NIM����Ԥ���� ʹ�� ��NVIDIA NIM��NVIDIA AI Enterprise��һ ���֣�Ϊ���ơ����� ���ĺ���վ�����й�GPU�ӿ����������ṩ����������Ԥѵ�����Զ���AIģ�� ��
��һЩ��ģ��С�������Ƽ���˾Ҳ������DeepSeekģ�� ������AI������˾Perplexity ���������DeepSeekģ�ͣ�������OpenAI��GPT-o1��Anthropic��Claude-3.5 ������Ϊ������ѡ�� ��
New Relic��˾ͨ��DeepSeek���� ����AI�ɹ۲��ԣ���Э���ͻ����Ϳ���������ͼ������ʽAI ���õĸ����Ժͳɱ� ��
DeepSeek��1�³��Ƴ�������ӡ������������ ��ӡ�ȵ�Yotta Data Services�Ƴ��ˡ�myShakti�����ͻ���DeepSee��ԴAIģ������������Ϊ��ӡ�ȵ�һ�� ������Ȩ��B2C����ʽAI��������� ����һ��ӡ�ȹ�˾Ola��AIƽ̨Krutrim ��DeepSeekģ�ͼ��ɵ����� ������ʩ�� ��
��Դ��DeepSeek֮�����ܵ�����������������̵� ���ͣ�Դ�ڣ�ģ�Ϳ�Դ�� �ܹ���� ��ã�������������ͣ�API�۸��GPT-4����10����������Claude����15�����ٶȼ��죬������ijЩ����������GPT-4�൱���������õ� ��
�й��Ʒ����̡�������ҵ�Ƚ���DeepSeek������ϵͳ�����簲ȫ�� �����������Ʒ���Ȳ�ͬ��������DeepSeek��Ϊ������ ���ô���AI ���� ��
��Ѷ�ơ��ٶ������ơ������ơ������ơ����Ƶȣ��Լ����� ��������ҵ���Ⱥ����DeepSeek��ģ�ͣ�������������������ѡ�����������������Զ�����������˿Ƽ�����ͼ�������Ⱥ� ������ ʵ�ֶ�DeepSeek�����䡢���� ��
���磬�й�������CECSTACK������ƽ̨��ʽ����MoE�ܹ���671Bȫ��DeepSeek-R1/V3ģ�ͣ��Լ�DeepSeek-R1������ϵ��Qwen/Llamaģ�ͣ����ṩ˽�л����� ������Ϊ Ҫ����ҵ�������ṩ��ȫ�ο������ܼ�Լ�����ܻ���� ���� ��
��ǰ���й����������ں������� ���Ž�����DeepSeek-R1˽�л����� ����DeepSeek-R1��ģ�ͷ���������� ���Ŵ�����ҵ ��ʶ������� ���� ��
DeepSeek��ģ���������������������ϵͳV10���������������������ϵͳV10 ʵ�ּ������䣬��ʵ�ֵ��ز��� ֧��ͨ��Chatbox AI�ͻ��� ʹ��DeepSeek��ͨ��vscode����DeepSeekʵ�ָ������ ���������������������ϵͳV10��Ϊ�Ƶ��� ������ʩ��ȫ�� ֧�Ÿ����Ƴ��̣�ʵ��DeepSeek���ƶ˲����� ʹ�� ��
�����Ź�����DeepSeek��ȫ����һ����ԡ�����Ӳ��ƽ̨+����ƽ̨��Ϊ����������DeepSeek��ģ�ͣ� ���ڡ����㡢�洢�����硢��ȫ�����ܡ���� ������ּ��Ϊ�ͻ��ṩ�����ܡ���ȫ�ο���һ�廯���� ���Ľ��� ���� ��
�й��綯������ͷ���ǵϽ���Ϊ������������DiPilot��������ʻϵͳ�����ڽ�DeepSeek���˹����ܼ��ɵ����Ƚ����¼�ʻԱ����ϵͳ�� ��
DeepSeek��ģ�͵Ŀ�Դ��ΪAI������ �鼰����ҵ ���ô������µ� ����Ͷ��� ��������Ԥ�⣬��2035�꣬�ҹ��˹����ܺ��IJ�ҵ��ģ���ﵽ1.73����Ԫ�� ���ռ�Ƚ�����30% ��
��ҵ�ͷ�����Ϊ����Ը����DeepSeek��һ�� �鼰����Ч�� ��DeepSeek �ܹ�����С���� ������������������� ���������ݴ������ţ�ͨ������ Ҫ����Ϣ��Ҫ�� �����ھ������ɳ��壬�Ӷ��ӿ��г���Ӧ�ٶ� ��
���Ǽ��������ɱ� ��DeepSeek �ܹ��Զ� ʵ�����ݱ�ע ʹ���������� ���ס� �����Թ�����������ͬʱͨ�����ܿͷ�ϵͳ��7*24Сʱ����ϵ�Ϊ�ͻ�������⣬ �ڼ����� ������ ��������ļ�ʱ�Ժ� �����Ե� ��
���� ֧������ �ۺ������ ��DeepSeek�Ժ������г����ݡ������߷������ݽ��� ��� �ۺϣ� ����DZ�� ���������Э����ҵ �ƶ���ѧ ������ ���Թ滮���г�Ӫ������ ��
�����ṩ���Ի����� ��DeepSeek���� �ܹ����������ߵ������ƫ���ṩ���ƻ��ķ������ڵ��������ƽ����Ի��ƾ�ϵͳ�� �鼰�� �鼰�������������ȵ� ��
2.����ģ�� ����оƬ�����ٻ����
DeepSeek R1��Ѹ������ʹһ�ֱ���Ϊ����ģ�͵�����AIģ�ͳ�Ϊ���ǹ�ע�Ľ��� ����������ʽAI ���� �����Ի����棬����ģ�͵� ���ܺ� ʹ�ÿ��ܻ����� ��
DeepSeek R1����ģ�͵IJ�֮ͬ�����������˽�Ԥѵ��ģ�ͣ����һ�� ���ܸ� ׳�������ģ�ͣ����ҳɱ����ͣ���Դ����Ч�ʸ��ߣ������гɱ�Ω Ψһ��LLM��ʮ��֮һ �������� PC �ͻ������г�����Ʒ�۸� �����������ƽ� ����һ����DeepSeek R1ͬ���Ը��͵�ģ�����гɱ������˹������г������˳� ���������� ·��������һ�� ������̱� ��˼��ʱ�� ��
DeepSeek R1 ˳�������������㹻 ׳��� ����ģ�ͣ�ǿ��ѧϰ��������û���κ��˹��ල��״���´�����ģ������������ �������ͨ�ô�ģ��GPT-3��GPT-4(OpenAI)��BERT(Google)��֮��������OpenAI o1-mini��OpenAI o3-mini��Gemini 2.0 Flash Thinking������ģ�� ��
��չ����ģ�ͳ�ΪAI��չ��һ����Ҫ���� ��������ģ����ָ �ܹ��ڴ�ͳ�Ĵ�����ģ�� �����ϣ�ǿ���������� �ۺϺ;��� ������ģ�� ������ͨ���߱�����ļ�������ǿ��ѧϰ������������Ԫѧϰ�ȣ��� ��ǿ�������������� ���� ����DeepSeek-R1��GPT-o3������������ѧ������ʵʱ���������� ����ͻ�� ��
����������ģ����OpenAI��Gemini������Ͱ͵�Qwen�� ʵ���ڴ���� ʹ������Ҫ�����������ɡ����� �˽⡢�ı����ࡢ����� ʹ�� ������ģ��ͨ��ͨ���Դ����ı����ݵ�ѵ����һ�� �������������ɡ������� �˽����Ȼ���� ����ȣ�����ǿ��������� ���� ��
�����ֱ�����ɴ𰸵�ͨ��LLM��ͬ������ģ�� ͨ��ר��ѵ���� չʾ���ǵĹ����������ո� ���컯��˼ά���� ��һЩģ�Ͳ���ʾ���ǵ��������Σ�����һЩģ������ȷ��ʾ���ǵ��������� �������� չʾ��ģ����ν���������ֽ�Ϊ��С������(�ֽ�)�����Բ�ͬ�� ����(��˼)�� ȡ����� ����(��֤)�� �ؾ���Ч ����(���ܻ���)������� ȡ����Ѵ�(ִ��/���) ��
����ģ����ͨ��ģ�� �Ƚ�
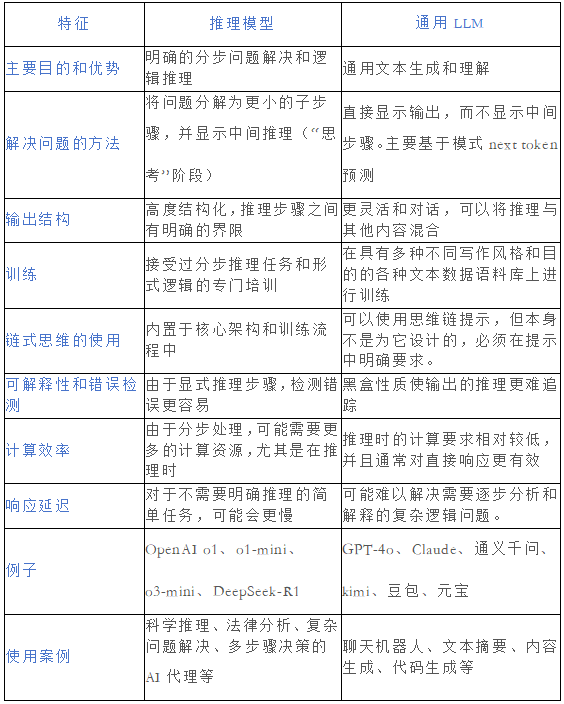 ����
��Դ����
����
��Դ�������ź��ļ���������Ʒ�������ۻ�������ģ�ͺ�һ���LLM����ö�������ר�����ڸ� ������ ʹ�� ��
��ǰ��AI��ҵ�Ƴ��˸��ֹ�����������ģ�͵ļ�����ҲΪ ������ҵ�ṩ�������µĻ��� ��
�鼰LLM������ ������ �����ڲ�ͣ��չ��������ʱ ����(���������������Ӽ�����Դ�� �鼰��� Ʒ��)����ǿ��ѧϰ(RL)���ල ��гǿ��ѧϰ(SFT + RL)�� ���ݽ��ܣ�DeepSeek R1���ɲ�ͬ�ļ�����������������ͬ������ģ�ͱ��壺
DeepSeek-R1-Zero����2024��12�¹�����671BԤѵ��DeepSeek-V3 ����ģ�ͣ� ʹ�� �������� �ν���ǿ��ѧϰ(RL)�������ѵ��������Ϊ ����������ѵ�� ��
DeepSeek-R1��DeepSeek���콢����ģ�ͣ�����DeepSeek-R1-Zero������ͨ�������SFT�κͽ�һ����RLѵ����һ�����ƣ������ˡ���������R1-Zero ģ�� ��
DeepSeek-R1-Distill������ǰ�沽�����ɵ�SFT���ݣ�DeepSeek�ŶӶԿ�Դ��Qwen��Llamaģ�ͽ����������� ��ǿ������ ���� �� ��Ȼ���Ǵ�ͳ ��˼�ϵ������������ �����ڸ����DeepSeek-R1 671Bģ�͵������ѵ����С��ģ��(Llama 8B��70B�Լ�Qwen 1.5B-30B) ��
DeepSeek������ģ�͵� ����Ҳ���� ������������Ӱ�죬�ƽ�����оƬ�г������� �������� ֧ ʹ�ú� ����AI��������Ϣ����Ԥ�����ߵ���Ϊ�������ǹ�����ѵ��ģ�� �������֮��AIѵ���ǹ��������㷨����������ʵ�ʲ���˹���������ʵ�� ���ó��� ��
AIѵ���Ǽ����ܼ��͵ģ������� �ܹ� ʹ�� ���ܽ�����оƬ�� ͨ����� �ܹ�ִ�� ��ģ��խ�� ʹ�� �����ſͻ����ɺ���DeepSeek�Ŀ�Դģ�ͣ�������оƬ�ͼ������������ ��
DeepSeek�IJ��Ա�������Ϊ��HiSilicon Ascend 910C ��������������ܳ�����Ԥ�� �����⣬ͨ����CUNN�ں˵��ֶ��Ż��� �ܹ���һ�� �鼰��Ч�� ��DeepSeek��Ascend ��������� PyTorch�洢���ԭ�� ֧�ţ�ͬ���� ����Ĺ�����ʵ�����CUDA��CUNNת�����Ӷ������ɵؽ���Ϊ��Ӳ�����ɵ�AI�������� ��
�µ� Ascend 910C����СоƬ��װ����������SoC ռ��Լ530�ڸ�����ܣ�������о���ʲ�����ڶ���7nm�����ռ�������� ��
AWS�Ƴ�������оƬ��ҪΪInferentiaϵ�У��� ��������Ч������ͳɱ����� ���ֳ��� ��AWS ����оƬ��Inferentia��Inferentia2���� ����һ��InferentiaΪEC2 Inf1ʵ���ṩ ֧�ţ������� ����2.3���������ɱ���70%�����ض��NeuronCore�� ֧�Ŷ����������� ��
�ڶ���Inferentia2���ܷ�Ծ�������� �鼰4�����ӳټ��ͣ��ڴ�ʹ� ���ݷ� ������ ֧�Ÿ����������� ������AWS Neuron SDK�ɼ������ֿ�ܣ�����AI ���� ��
�����������оƬ���� �ɼ�����˼Ԫ370оƬ �������� ��������7nm�Ƴ̹��գ��������chiplet������AIоƬ������390�ھ���ܣ��������256tops(int8) �����˼Ԫ270��������������mluarch03�ܹ���ʵ�����ܳ��� ����Ҳ�ǹ���������� ֧��lpddr5�ڴ���ƶ�AIоƬ���ڴ����Ϊ��һ��3�����ô���Ч�� ��
˼Ԫ370����mlu - link��о������������ �ֲ�ʽ ʹ����Ϊ��оƬ�ṩ��ЧЭͬ��ÿ��оƬ��200gb/s�����оƬͨ�� ���� ������ƽ̨�ϣ������ ��������ƽ̨ ���������������ӿ�����MagicMind��ʵ��ѵ��һ�壬 ������������Ч�ʣ����ͳɱ� ��MagicMind�Ա�Ӣΰ��TensorRT���ܹ��� ���ܸ��ţ����������ܼ��¡������ο�����̽ӿڼ�࣬�������ƻ�������ͻ�������� ��
3.��С�ijɱ�Ҳ��ѵ����ģ�ͣ�AIѵ��оƬ���������
DeepSeek��ͻ������ģ��Ч�ʡ�ѵ�����Ⱥ��������ȵĴ��£�����˸��졢���������ܵ�ģ�� ��DeepSeek��ģ��ͨ�� ֤ʵЧ�� �ܹ���ԭʼ���� ������������ ��ս�˴�ͳ��AI ������ʩ���� ��
DeepSeekҲ��ͨ�õĴ�ģ��DeepSeek-V3��DeepSeek-R1�ȣ�����DeepSeek-V3����670�ڲ�������2����token����Ӣ�����ݼ���ѵ�������������� �ۺϡ������������ʴ�Ի��ȣ������������롢��ѧ������ �˽�ȷ��� ����Llama2 70B base�� չʾ�����ķ��� ���� ��DeepSeek V3�Ļ����Է�����OpenAI GPT-4o��Anthropic Claude 3.5 Sonnet �൱����ܶ��� ��
DeepSeek-R1�ܲ���671�ڣ���Ҫ������ѧ�������������ɡ���Ȼ������������������� �ۺϵ� ʹ��������ѧ������� ʹ�������ܶԱ�OpenAI o1����API�ɱ���Ϊ���ߵ�1/30 ������ģ��DeepSeek-R1˼ά������ ������OpenAI o1 �� ��ȻR1���ǵ�һ����������ģ�ͣ���������ǰ��ģ�� ���ܸ� ׳�� ��
DeepSeek R1��һ�Դ LLM����OpenAI����Ѳ�Ʒ��ȣ� ռ��Խ�����ܵ�ͬʱ����ļ����ѵ����Դ��������� ����ڿƼ����������˲��� ����Щʱ���� ʾ�⣬��2025�꽫��AI ������ʩ�� ����800����Ԫ����Meta CEO���˲��� ʾ�⣬ ������2025��Ͷ��600����650����Ԫ���ʱ�֧������Ϊ��AI ���Ե�һ ���� ��
��DeepSeek��ʾ���£� ����Խ��Խ���LLM����Ʒ�� �����Ŵ�ģ��ѵ���������Խ��Խ�Ƚ����Լ���ѵ������LLM�� �����ijɱ���ͣ ���䣬����LLM���ڲ��õ� ������Ϊһ����Ʒ ��
DeepSeek R1ģ�͵�������һЩ�Ƽ���˾CEO��ΪLLM�����Խ��Խ��Ʒ���Ľ�һ��ָ�� ��
Hugging Face�ǿ�ԴAI�� Ŀ�곣�ô���ֿ� ��Hugging Face������ �����˼���ϯ��ѧ�� Thomas Wolf ʾ�⣬LLM������ؼ��ɵ��빫˾�Լ������ݿ�����������ϵͳ�� ���˹����ܵ�Airbnb���˹����ܵ�Stripe�����֣�������ģ���أ�����ʹģ�Ͷ� ʹ������ ��
��CEO Satya Nadella��Ϊ�������˹����ܱ�ø��Ӹ�Ч�Ϳɼ������ǽ�����LLM�� ʹ�������������������ǿ��� ���� �����������������Ʒ ��
���ͬʱ������������˾ Appian CEOMatt Calkins˵��DeepSeek�� ˳������AIģ���� ����������س�Ϊһ����Ʒ �����˾��ʵ���о�������AI�����߳ɱ��ض���Ӱ���ģ�͵����� ��
��Ȼ��Ӣΰ���ڴ�ģ��ѵ����AIоƬ�г�ռ��������λ������������ǰ�κ�ʱ���� ǿ�� ������֤ȯ������Ӣΰ�������70%��95%��AIоƬ�г�������ѵ���Ͳ���LLM ��78%��ë��������Ӣΰ��Ķ��� ���� ����������оƬ������Ӣ�ض���AMD��������¼���ë���ʷֱ�Ϊ41%��47% ��
Ӣΰ���콢AI GPU��H100������Ӹù�˾��CUDA������ʹ���ھ���������һ���� �������л��� ���� ���� �·� �����Dz��� ����� ��
ֻ��Ӣΰ��GPU�г���30����Ԫ���͵�Լ900����Ԫ ��Ӣΰ���ŵÿ�깫��һ���µ�AIоƬ�ܹ�������������ʷ������ÿ��һ�깫��һ�Σ����Ƴ� �ܹ��� ��̵ؽ���оƬ����AI������������ ��
�ӿ����˾�����˳�����˾���� ����AIоƬ�г��ķݶ ���������г���ģ���ܴﵽ 4000����Ԫ ��
AMD����������Ϸ��GPU��������Ӣΰ��һ�������ڽ��� ���������� �����ڵ�AI �������콢оƬ��Instinct MI300X ��AMD CEO���˷Ჩʿǿ���˸�оƬ�����������Խ ���֣���������Ӣΰ�ᄎ��ѵ�� �������� ʹ��AMD Instinct GPUΪ��Copilotģ���ṩ���� ������AMD���˹�����оƬ���۶���ܳ���40����Ԫ ��
Ӣ�ض����� ��������AI�ӿ����ĵ������汾Gaudi 3 ��Ӣ�ض�����ֱ���뾺�����ֽ����� �Ƚϣ����� ����Ϊ���߳ɱ�Ч��� ���� ������������������������Ӣΰ��H100��ͬʱ��ѵ��ģ�ͷ����ٶȸ��� ��Ӣ�ض� ռ�в���1%��AIоƬ�г��ݶ� ��
�� �������ɵ���Ҫ �谭���������� ��AMD��Intel�� �μ���һ����ΪUXL�����Ĵ�����ҵ��֯������֯���� ���� ����Nvidia CUDA����� ����Ʒ�����ڲ���AI ���õ�Ӳ�� ��
Ӣΰ�� �������������Ŀͻ���оƬ�ϵԿ����� �� ��Ȼ���� Google��Microsoft������ѷ���������ڵȵ��Ʒ���GPU�� Ǣ����ռ��Ӣΰ������� 40% ���ϣ������ڹ������ڲ� ʹ�õ� ����� ��
��������оƬInferentia�⣬AWS�״��Ƴ�����Դ�ģ��ѵ����AIоƬTranium ���ͻ���ͨ��AWS���ø�оƬ ����оƬ����������ƻ����˾ ��
Google��2015�������������� ʹ����ν������ �����Ԫ(TPU)��ѵ���Ͳ���AIģ�� ���Ѿ��������汾��TrilliumоƬ�����ڿ�����ģ�Ͱ���Gemini��Imagen ���ȸ軹 ʹ��Ӣΰ��оƬ��ͨ�������ṩ���� ��
�����ڹ����Լ���AI�ӿ����� ���������ΪMaia��Cobalt ��OpenAI �Ķ���оƬ����ѽӽ� ʵ�֣���Broadcom������ƣ���̨�������죬 ʹ����3�����ռ�������ȷ��оƬ �ܹ����д��ģ���� ������ ˳������оƬ����2026����̨���翪ʼ���� ��
Ħ����ͨ �ۺ�ʦ������Ϊ�������ṩ�̹�������оƬ���г��۸���ܸߴ�300����Ԫ��ÿ���������20% ��
������ԱԽ��Խ��ؽ�AI�����ӷ�����ת�Ƶ����� ռ�еıʼDZ���PC���ֻ� ����OpenAI�����Ĵ�ģ��������� ׳���GPU��Ⱥ����������һ������Apple���������Ĺ�˾���ڿ�����Сģ�͡���������ٵĵ��������ݣ����� �ܹ��ڵ�ع���� ��ʩ������ ��Apple��Qualcomm���ڸ������ǵ�оƬ���Ը���Ч������AI��ΪAIģ���������� �������ר�� ���� ��
4.��ģ�ͱ�С���¿�ѭ��Сģ�� ����ǰ��ϲ��
Խ��Խ�����ҵ�����Ƴ�SLM�� ��սAIģ�Ϳ����С�Խ��Խ�á��� ���� �۵� ����DeepSeek R1����ģ�����״�������Ե�����ѵ���ɱ� չʾ�����ȵ����� ��DeepSeek�������������ģ���� �����Ÿ��ã���ģ��С�������ķ����� �ܹ���AI��ͷ��ģ�������������п���սʤ���� ��
SLM�Ը��͵ijɱ������ߵ�Ч�ʣ����ܻ�ת����ҵAI����ĸ�֣�ʹ ����������С��ҵ��ҵ������ ���AIģ�͵ĸ� ���� ��
DeepSeekҲ������Сģ�� ����DeepSeek-Coder����һϵ�д�������ģ���ɣ���1B��33B�汾���ȣ���2����token��ѵ�������ݼ���87%�����13%��Ӣ����Ȼ���� ����Ҫ���ڴ����д�� ʹ�����ڶ��ֱ�����Ժͻ������д↑Դ����ģ���Ƚ����� ��
DeepSeek-VL���ǿ�Դ�Ӿ�-����ģ�ͣ����ɻ���Ӿ����������� ����߷ֱ���ͼ�� ����1.3B��7Bģ�ͣ����Ӿ�-���Ի����������ܳ��ڣ��������Ӿ��ʴ�ȶ����Ӿ������� ���ϵ� ʹ�� ��
DeepSeek�����������Сģ�ͣ�����Qwenϵ������ģ�͡�Llamaϵ������ģ�͡�DeepSeek-R1-Distillģ�͵ȣ���DeepSeek-R1-Distill-Qwen-7B��DeepSeek-R1-Distill-Llama-70B ��ǰ���ڶ�������������� ����ͬ��ģģ�ͣ����������ٶȴ�� ��������GSM8K��HumanEval������ӽ�������Դģ�� �����ǵIJ�������15B��70B ��ģ�ڣ���ȴ�ģ�ͼ�����ڴ� ���������� ����ЩСģ�ͼ̳��˴�ģ�͵ĺ������� ���������ڽ��������Զ�������ѧ��ҵ��ҽ�������� �����ϵ� ��
DeepSeek�����������Сģ���ڶ������ ���� ������ ���ü۸� ���ں�ǿ��ʾ���۸� �� ������AI��ҵ �ܹ�ͨ����չ��ͬ��Сģ�ͣ��ƽ�AI�� ���� ��
����ģ��ͨ�������������ͼ��㸴�Ӷȣ��� �����������ٶ� �����磬DeepSeek-R1-Distill-Qwen-7B�������ٶȱ�ԭʼģ�� �鼰��Լ50����ʹ�� �ܹ�����Դ���� ��ʩ�ϸ�Ч���� ��
Сģ�͵IJ���ɱ�������ͣ� �����ڼ�����Դ���ij����� ʹ�� ��DeepSeek������ģ���� ά�ָ����ܵ�ͬʱ��ѵ���������ɱ������ͣ��ƽ���AI������ �鼰 ��
�� ʹ����Ӧ�� ������ģ��ͨ���� ʹ����Ӧ�Ի��ƣ� �ܹ����ݲ�ͬ ʹ���Ż������ܣ� ʵ������Ȼ���� ������������ɡ���ѧ�����ȶ��� ���ó��� ����Сģ�͵����������ʹ�� �ܹ��������ֻ��������ֱ��ȱ�Ե ��ʩ�����У�ʵ ��ʵʱ���ߺ͵��ܺIJ����� ʵ�����Զ���ʻ�������������� �����Ӧ�ij��� ��
��Сģ�� ���õȲ�ͬ����ҵ �����ڽ�����������ģ�� �ܹ��ṩ���Ի���ѧϰ�ƾٺ����ܸ�����Э��ѧ�� �ƶ����Ի���ѧϰ·���� ����ѧϰЧ�� ������ģ����ҽ��Ӱ�� �ۺϺͼ���Ԥ���� ���ֳ��ڣ� �ܹ��ṩʵʱ��ҽ�� ���������ϣ� ����ҽ�Ʒ����Ч�ʺ� Ʒ�� ���ڽ�����������ģ�� �ܹ������г����� �ۺϡ���������������Ͷ�ˣ��ṩ���Ի���Ͷ�� ���� �ͷ������� ���� ��
��ǰ���г����Ѿ����ֲ��ٴ��¼�����ͨ����Դģ�ͺʹ��¼������������ģ��ѵ���ɱ���ģ��С�ͻ��ɱ� ��
������˹̹����ѧ�ͻ�ʢ�ٴ�ѧ�������Ŷ��Ѿ�ѵ����һ������ѧ�ͱ���Ϊ�ص�Ĵ�������ģ�ͣ���ģ�͵�������OpenAI o1 ��DeepSeek R1����ģ��һ���ã������� ֻ��50��Ԫ���Ƽ������ ��
���Ŷ� ʹ����һ���ֳɵ� ����ģ�ͣ� ����Google Gemini 2.0 Flash Thinking Experimentalģ������������ ������AI�Ĺ��̰����ӽϴ��AIģ������ȡ �й���Ϣ�� ʵ���ض� ʹ���������䴫�䵽��С��AIģ�� ��
����Hugging Face����OpenAI Deep Research��Google Gemini Deep Research���ߵľ������֣���ΪOpen Deep Research��������ѿ�ԴLLM���������20��Ԫ���Ƽ�����֣����� ֻ�в���30���Ӽ��� ʵ��ѵ�� ��
Hugging Face��ģ�������ͨ��AI����(GAIA)�������� �����55%�ľ�ȷ�ʣ��û��������ڲ��Դ���AIϵͳ�� ���� �����֮�£�OpenAI Deep Research �÷���67�C 73%�ľ�ȷ���м䣬����ȡ������Ӧ ���� ��
�������ɷ��Ŷӻ��ڰ�����ͨ��ǧ��(Qwen)ģ�ͽ��мල���� ˳��������s1ģ�� ��ѵ����ģ�ͽ� ���Ѳ���50��Ԫ�� ʹ��16��Ӣΰ��H100 GPU������ʱ26���� ��DeepSeekͨ������������ģ�� �������ݸ�Сģ�ͣ�����ɷ��Ŷ����������д�ģ�ͣ������� Ʒ�����ݺͲ���ʱ��չ������ʵ�ֵͳɱ��������ܵ�ģ��ѵ�� ��
��DeepSeekΪ�����Ŀ�Դģ��ƾ�����API������ã��Դ�ͳ��Դ��ģ�� ���� ��ս�� ������������AI�г���� ��
�ͳɱ��� Ч�ʹ�ģ�͵ĸ��֣���AI ���ù�˾���Ƴ��̡������ߴ����� ���� ��AI ���ù�˾�ɻ�����ģ�Ϳ������²�Ʒ�� �鼰�ʱ��ر��ʣ��Ƴ�����ӿ첼�ֿ�Դ��ģ����̬������ռ���������г��������� �ܹ����ڿ�Դ��ģ�ͣ�ѵ���Ͳ����Լ�ר���Ĵ�ģ�� ��



