����ChatGPT ����AI��ģ�Ϳ��⣺Ϊ�����Ż���֧�ֹ���CPUѵ�� |
|
�齭·����
��
2023��3��15��
����
ת��
�����漣Ӱ����
|
|
�������ı�ǩ��ChatGPT,����AI |
ChatGPT���� ������GPT-4ģ�ͣ�AI �������� ׳�������ⷽ��Ҳ��Ѹ���ϣ��й��������ChatGPT�����ˣ������廪��ѧ �����ƽ� �����ɸ�УAI �ɼ�ת����ChatGLM��ʼ�ڲ� ��
�ݽ��ܣ��Ի������� ChatGLM(alpha�ڲ�棺QAGLM)������һ�������ʴ�ͶԻ� ���ܵ�ǧ����Ӣ����ģ���� ��������Ľ������Ż������ѿ����������ڲ⣬���������� �����ڲ� ��ģ ��

���ͬʱ���̿�Դ GLM-130B ǧ�ڻ���ģ��֮��������ʽ��Դ���µ���Ӣ˫��Ի� GLM ģ�ͣ� ChatGLM-6B�� ����ģ������������������ �ܹ������Ѽ����Կ��Ͻ��е��ز���(INT4 ������������� ֻ�� 6GB �Դ�) ��
ͨ��Լ 1T ��ʶ������Ӣ˫��ѵ�������Լල���� �������������෴��ǿ��ѧϰ�ȼ����ļӳ֣�62 �ڲ����� ChatGLM-6B ��Ȼ��ģ ����ǧ��ģ�ͣ����������������߲�����ż��������Ѿ��������൱ �������ƫ�õ� �� ��
ChatGLM �ο��� ChatGPT �����˼·����ǧ�ڻ���ģ�� GLM-130B1?��ע���˴���Ԥѵ����ͨ���мල��(Supervised Fine-Tuning)�ȼ���ʵ������ ������� ��
ChatGLM Ŀǰ�汾ģ�͵� ���� ������Ҫ ��Դ�ڶ��ص�ǧ�ڻ���ģ�� GLM-130B �����Dz�ͬ�� BERT��GPT-3 �Լ� T5 �ļܹ�����һ�������� ָ�꺯�����Իع�Ԥѵ��ģ�� ��
2022��8�£�������̽�����ҵ�翪���� ռ��1300�ڲ�������Ӣ˫�� �ܼ�ģ�� GLM-130B1����ģ����һЩ���ص����ƣ�
˫�?ͬʱ ֧�����ĺ�Ӣ�� ��
�߾���(Ӣ��)��?�ڹ�����Ӣ����Ȼ���� LAMBADA��MMLU �� Big-bench-lite ������ GPT-3 175B(API: davinci������ģ��)��OPT-175B �� BLOOM-176B ��
�߾���(����)��?��7�������� CLUE ���ݼ���5�������� FewCLUE ���ݼ����Զ������� ERNIE TITAN 3.0 260B �� YUAN 1.0-245B ��
���������?��ʵ�� INT4 ������ǧ��ģ�ͣ� ֧����һ̨ 4 �� 3090 �� 8 �� 2080Ti ���������� ����� ������������ ��
�ɸ����ԣ�?ȫ�� ���(���� 30 �� ʹ��)����ͨ�����ǵĿ�Դ�����ģ�Ͳ������� ��
��ƽ̨��? ֧���ڹ����ĺ��� DCU����Ϊ�N�� 910 ������ �������������Ӣΰ��оƬ�Ͻ���ѵ�������� ��
2022��11�£�˹̹����ѧ��ģ�� ���Ķ� ���30��������ģ�ͽ�����ȫ��λ�IJ���2��GLM-130B ������Ψһ��ѡ�Ĵ�ģ�� ��
���� OpenAI���ȸ���ԡ�����Ӣΰ�����ĸ���ģ�Ͷ����У�����������ʾ GLM-130B �ھ�ȷ�Ժ� ������ָ������ GPT-3 175B (davinci) �ӽ����ƽ��³���Ժ�У�����ȫ��ǧ�ڹ�ģ�Ļ�����ģ��(��Ϊ��ƽ���գ�ֻ������ָ�� ��ʾ��ģ��)�� ���ֲ���(��ͼ) ��
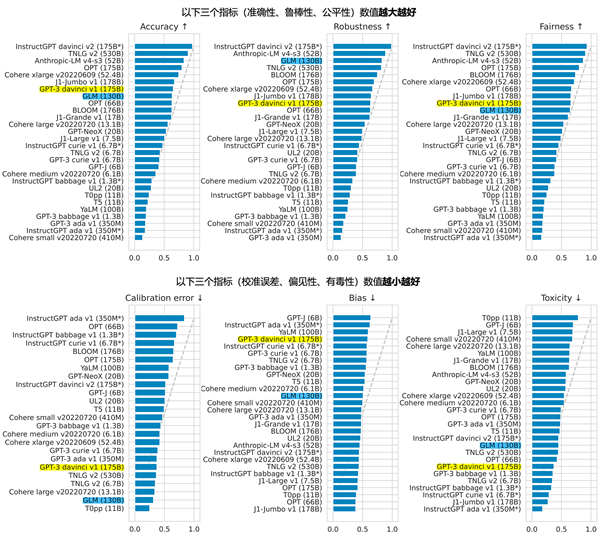 ͼ1. ˹̹����ѧ
����ģ��
���Ķ�
��� 30 ����ģ�͵IJ���
���(2022��11��)
ͼ1. ˹̹����ѧ
����ģ��
���Ķ�
��� 30 ����ģ�͵IJ���
���(2022��11��)


