在轻薄本上跑 Stable Diffusion 和端侧大模型?英特尔说没问题 |
|
珠江路在线
2023年8月23日
【
转载
】天龙八部3D影院
|
|
本文标签:英特尔,AI,轻薄本 |
无论被动还是 积极,大模型,AIGC,ChatGPT,Stable Diffusion,MidJourney 等等名词在大家的新闻列表里狂轰滥炸, 经历了上半年的惊喜、恐慌、等待和 担心之后,AIGC 现今已不是天降福音或者天网再临,人们开始正视它, 了解它,适度利用它 。
固然,这一轮 AIGC 浪潮重要 产生在云端,无论是 ChatGPT,还是文心一言,通义千问这类大语言模型 利用,亦或是 MidJourney 这类 AI 生成图片的 利用,还有不少像 Runway 这样 AI 生成视频的 利用,都需求联网,由于 AI 计算都 产生在千里之外的云端服务器上 。
毕竟普通而言,服务器端 能够提供的算力和存储,要远大于电脑端和手机端,但状况也并非绝对,响应快,无需联网的端侧 AI 毫无 疑难是另一个趋向,和云端 AI 能够 彼此互补 。
在前不久的小米年度 报告中,小米 独创人雷军 示意,小米 AI 大模型最新一个 13 亿参数大模型已经 顺利在手机当地跑通, 部分场景 能够媲美 60 亿参数模型在云端运行 后果 。
固然参数量不太大,但 注明了大模型在端侧的可行性和 后劲 。
在算力大得多的 PC 端,是不是也有端侧大模型等 AIGC 使用的可行性和 后劲呢?8 月 18 日,英特尔举办了一场技术分享会,着重分享了 2 个方面的信息:英特尔锐炫显卡 DX11 性能更新,并推出崭新英特尔 PresentMon Beta 工具,以及 展示英特尔在 AIGC 领域的发展 。

上一年英特尔锐炫台式机产品公布时,就承诺过英特尔锐炫显卡会 延续优化 晋级,带来更出众的体验 。
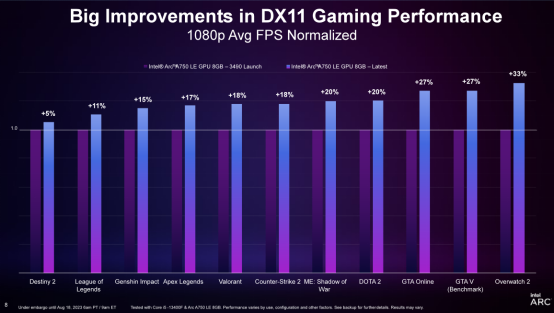
通过最新 Game On 驱动的公布,英特尔锐炫显卡在运行一系列 DX11 游戏的时候, 能够 获得 19% 的帧率 晋升,以及 均匀约 20% 的99th Percentile帧率流畅度 晋升(相较于首个驱动版本) 。此前购买 使用过英特尔锐炫 A750 显卡的消费者, 能够直接下载最新驱动,在《守望先锋 2》、《DOTA 2》、《Apex Legends》等游戏中 获得体验 晋级 。
关于在显卡 取舍上有点犹豫的消费者来说,1700 元档位上的锐炫 A750 显卡也成为了颇有竞争力的 取舍 。
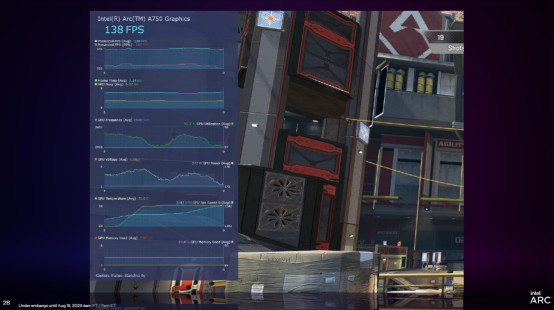
PresentMon Beta 则是英特尔推出的图形性能 综合工具,提供了 Overlay(叠加视图)等 性能, 能够在运行游戏时在屏幕上显示性能数据,协助发烧友实时遥测 GPU 的电压和温度等,实时 综合大量信息 。同时也 能够查看 99th Percentile 帧 工夫与 GPU 占用率图表 。
另外,PresentMon Beta 也带来了名为「GPU Busy」的崭新指标 。这里 能够解释一下,消费者通过它 能够看到 GPU 实际 使用了多少 工夫进行实际渲染而不是处于等待状态,或者在运行游戏的 PC 是不是处于 CPU 和 GPU 均衡 。
游戏是 PC 永恒的主题,而 AI 则是新晋的主题 。
实际上,这一轮 AIGC 浪潮 产生的主阵地 设施,便是 PC,无论是 ChatGPT,还是 MidJourney,或者 Stable Diffusion 等等 利用,包含基于大模型的微软 Office Copilot,亦或是金山办公的 WPS AI,都是在 PC 上才 能够 获得更好的体验 。
但 PC 相较于 其余 设施,诸如手机,平板和优势,不只在于屏幕更大,交互输入更高效,还在于芯片性能 。
在英特尔谈 PC 上的 AIGC 之前,我们关注到 PC 端侧跑 AIGC,一般便是用高性能游戏本去跑图,但轻薄本一般被排除在外 。
现在,英特尔明确 示意了,基于英特尔 解决器的轻薄本能跑大模型,也 能够跑大模型和 Stable Diffusion 。
英特尔基于 OpenVINO PyTorch (英特尔推出的一个开放源码工具包,旨在优化深度学习模型的推理性能,并将其部署到不同的硬件平台上)后端的 方案,通过 Pytorch API 让社区开源模型 能够很好地运行在英特尔的客户端 解决器、集成显卡、独立显卡和专用 AI 引擎上 。
比方开源的图像生成模型 Stable Diffusion (具体讲,是 Automatic1111 WebUI)就 能够通过这种 模式,在英特尔 CPU 和 GPU(包含集成显卡和独立显卡)上运行 FP16 精度的模型,消费者实现文字生成图片、图片生成图片以及 部分修复等 性能 。
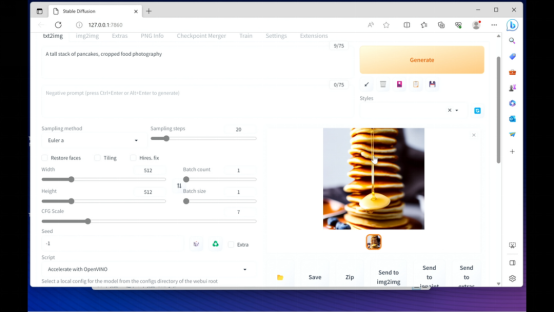 (图片来自:爱极物)
(图片来自:爱极物)比方这张 512×512 分辩率的蜂蜜薄饼图在英特尔 解决器轻薄本(只用 i7-13700H 的核显)上, 只有求十几秒就 能够生成出来 。
这重要得益于 13 代酷睿 解决器在核心数、性能、功耗比还有图形性能上的 遍及,以 14 核心 20 线程的 i7-13700H 解决器为例,它的 TDP 达到了 45W,集成的 Intel Iris Xe Graphics (96EU) 显卡也不容小觑 。
作为当前最高规格的核显之一,Intel Iris Xe Graphics (96EU) 相较于 Iris Plus 核显最高 64EU, 根本规格 晋升显而易见,FP16、FP32 浮点性能 晋升幅度高达 84%,还引入了 INT8 整数计算 威力 ,这些都 加强了它的 AI 图形计算 威力,也是英特尔轻薄本 能够很好 支撑 Stable Diffusion 的重要缘由 。
在以前,TDP 45W 左右的英特尔 解决器很难装进轻薄本,不过到了 13 代酷睿,已经浮现了一大批在 1.4KG 左右的轻薄本把 14 核心 20 线程的 i7-13700H 解决器乃至性能更高的 i7-13900H 解决器塞了进去,所以,在笔记本上跑 Stable Diffusion 快捷出图已经不是高性能独显游戏本的专属,今后轻薄本同样 能够胜任这项工作 。
固然,Stable Diffusion 本身重要跑在当地,轻薄本通过芯片性能的 晋升和优化来运行合乎逻辑,不过当地的端侧大模型则属于较为新生的事物 。
通过通过模型优化,减低了模型对硬件资源的需求,进而 晋升了模型的推理速度,英特尔让一些社区开源模型 能够很好地运行在个人电脑上 。
以大语言模型为例,英特尔通过第 13 代英特尔酷睿 解决器 XPU 的加快、low-bit 量化以及其它软件层面的优化,让最高达 160 亿参数的大语言模型,通过 BigDL-LLM 框架运行在 16GB 及以上内存容量的个人电脑上 。
固然离 ChatGPT3.5 的 1750 亿参数有量级差距,但毕竟 ChatGPT3.5 是跑在一万颗英伟达 V100 芯片构建的 AGI 网络集群上 。而这通过 BigDL-LLM 框架运行 160 亿参数大模型是跑在英特尔酷睿 i7-13700H 或 i7-13900H 这样为高性能轻薄本打造的 解决器上 。
不过这里也 能够看到,PC 端侧的大语言模型,也比手机端侧的大语言模型高一个量级 。
浮现了数十年的 PC,并非运行云端大模型的工具人,得益于硬件 遍及,英特尔 解决器 支撑的 PC 已经 能够 快捷对接新兴模型,兼容 HuggingFace 上的 Transformers 模型,当前已 教训证过的模型包含但不限于:LLAMA/LLAMA2、ChatGLM/ChatGLM2、MPT、Falcon、MOSS、Baichuan、QWen、Dolly、RedPajama、StarCoder、Whisper 等 。
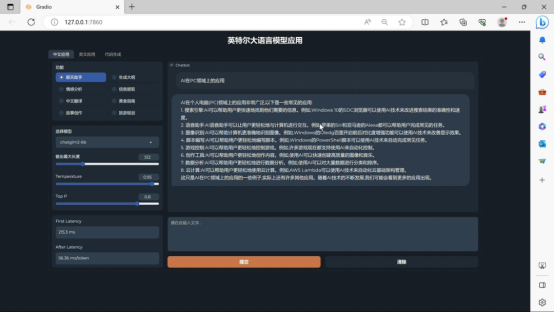 (图片来自:爱极物)
(图片来自:爱极物)在技术分享会现场,英特尔演示了基于酷睿 i7-13700H 设施跑大模型的 体现:ChatGLM-6b 能够做到首个 token 生成 first latency 241.7ms,后续 token 均匀生成率为 55.63ms/token 。在在自然语言 解决领域,「token」 是指文本中的一个 根本单元, 能够是一个单词、一个字、一个子词(subword)、一个标点符号,或者 其余 能够进行语义 解决的最小单元 。 能够看到,这个 解决器速度相当不错 。
当前还 能够得到的 信息是,英特尔的下一代 解决器 Meteor Lake 具备独特的 拆散式模块架构的优势,更好地为 AI 服务,包含像 Adobe Premiere Pro 中的自动再一次构图和场景编辑检测等多媒体 性能,并实现更有效的机器学习加快 。
固然 AIGC 是 2023 年的一个 要害词,然而 AI 并不新奇,并且也是英特尔这几年来 时常挂在嘴边的 要害词 。
更早之前的 AI 视频通话降噪,AI 视频通话背景降噪等等,其实都是 AI 的 利用 。
能够看到, 将来 解决器的竞争力,将不局限于核心数、线程数、主频这些, 是否更好地驱动 AI 性能,将成为愈发重要的维度,也会是今后消费者选购产品会考量的因素之一 。



