DeepSeek开源通用矩阵乘法库,300行代码加速V3、R1,R2被曝五月前问世 |
|
珠江路在线
2025年2月26日
【
转载
】传奇游戏网
|
|
本文标签:AI,python |
实用于 通例 AI 模型和 MoE 。
DeepSeek 的开源周已经进行到了第三天(前两天报导见文末「 有关浏览」) 。今日开源的 名目名叫 DeepGEMM,是一款 支撑密集型和专家混合(MoE)GEMM 的 FP8 GEMM 库,为 V3/R1 的训练和推理提供了 支撑,在 Hopper GPU 上 能够达到 1350+ FP8 TFLOPS 的计算性能 。

具体来说,DeepGEMM 是一个旨在实现简洁高效的 FP8 通用矩阵乘法(GEMM)的库,它采纳了 DeepSeek-V3 中提出的细粒度 scaling 技术 。该库 支撑一般 GEMM 以及专家混合(MoE)分组 GEMM 。该库采纳 CUDA 编写,在安装过程中无需编译,而是通过一个轻量级的 Just-In-Time(JIT)模块在运行时编译全部内核 。
当前,DeepGEMM 仅 支撑英伟达 Hopper 张量核心 。为了解决 FP8 张量核心累加不准确的问题,它采纳了 CUDA 核心的两级累加( 晋升)机制 。 只管它借鉴了 CUTLASS 和 CuTe 的一些概念,但幸免了对其模板或代数的重度依赖 。相反,该库的设计 重视简洁性,仅包含一个核心内核函数,代码量仅为 300 行 。这使其成为学习 Hopper FP8 矩阵乘法和优化技术的一个简洁且易于猎取的资源 。
只管设计轻量,DeepGEMM 在各种矩阵 形态上的性能与专家调优的库相当,甚至在某些状况下更优 。
开源地址:https://github.com/deepseek-ai/DeepGEMM
早期试用者评介说,「DeepGEMM 听起来就像是数学界的超级英雄 。它比高速计算器还快,比多项式方程还 壮大 。我试着用了一下,现在我的 GPU 都在 夸耀它的 1350+ TFLOPS,宛然已经 预备好 加入 AI 奥赛了!」
这个计算性能假如外加高 品质的数据,没准儿能 奉献更大的惊喜???
除了性能,「300 行代码的性能 超过了专家调优的内核」同样让不少人感到 惊异,有人认为「要么 DeepSeek 破解了 GPU 矩阵的神秘,要么我们方才见证了最高等级的编译器魔法 。」
看来,DeepSeek 团队里有一批 主宰编译器神秘技巧的顶级 GPU 工程师 。

还有人评介说,「DeepGEMM 正在转变我们 使用 FP8 GEMM 库的 模式,它简洁、 快捷且开源 。这正是 AI 计算的 将来 。」
在项 目标 奉献者列表中,有人发现了一个姓 Liang 的工程师,难道是 DeepSeek 独创人梁文锋( 实在性有待 验证)?? ?
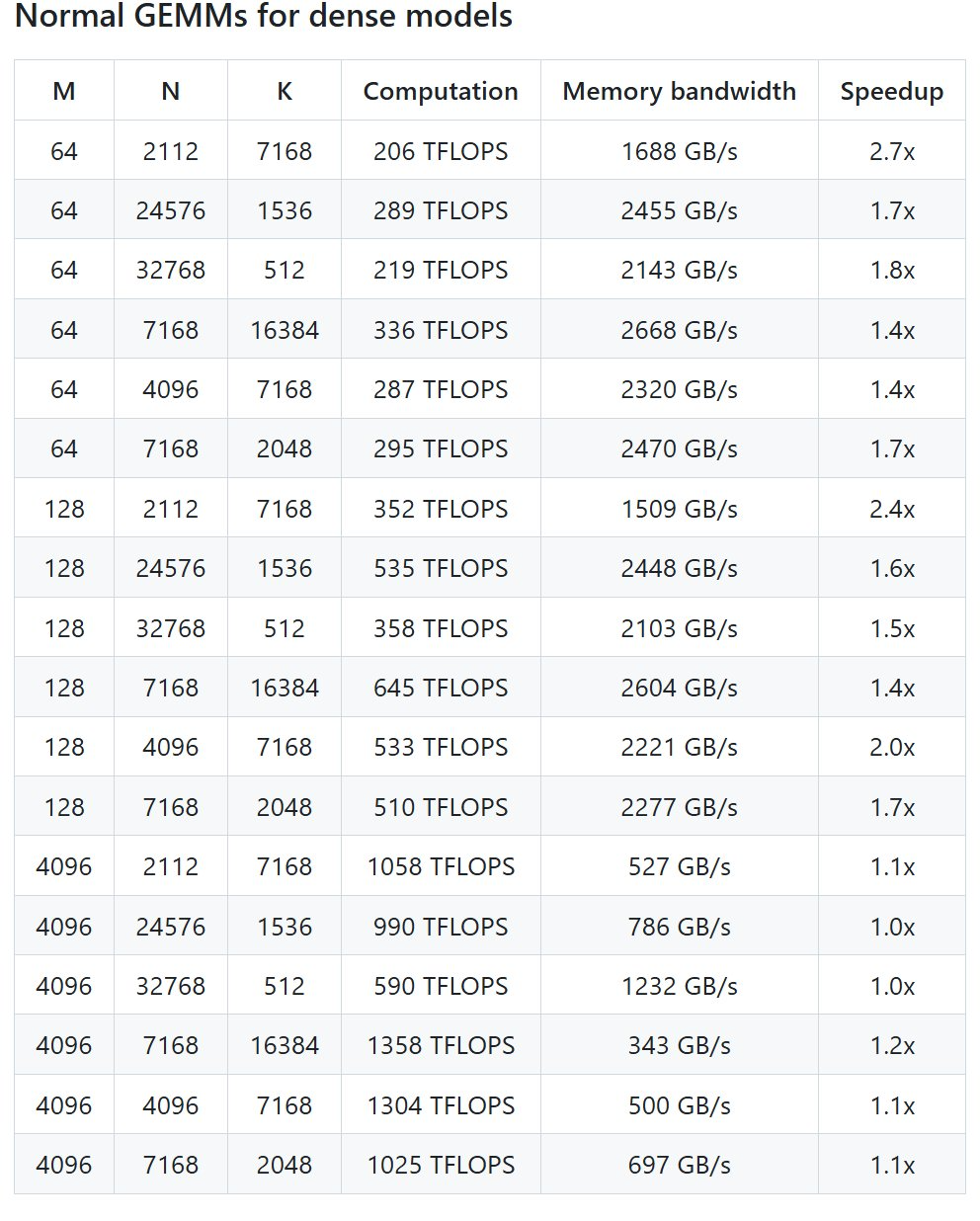
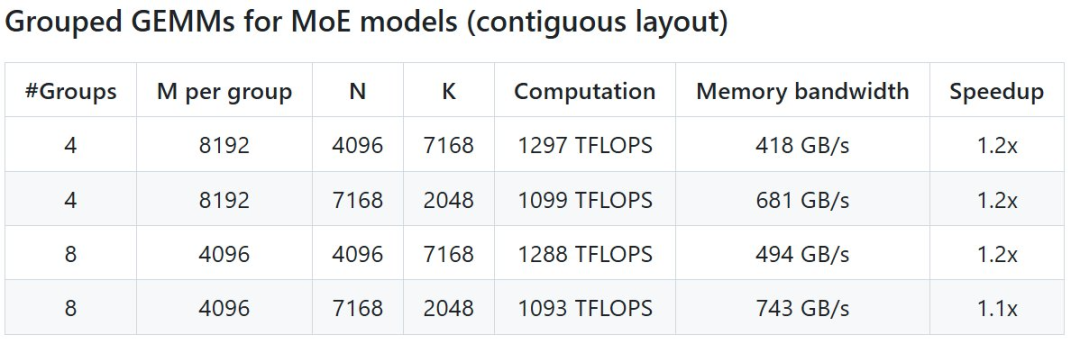
性能
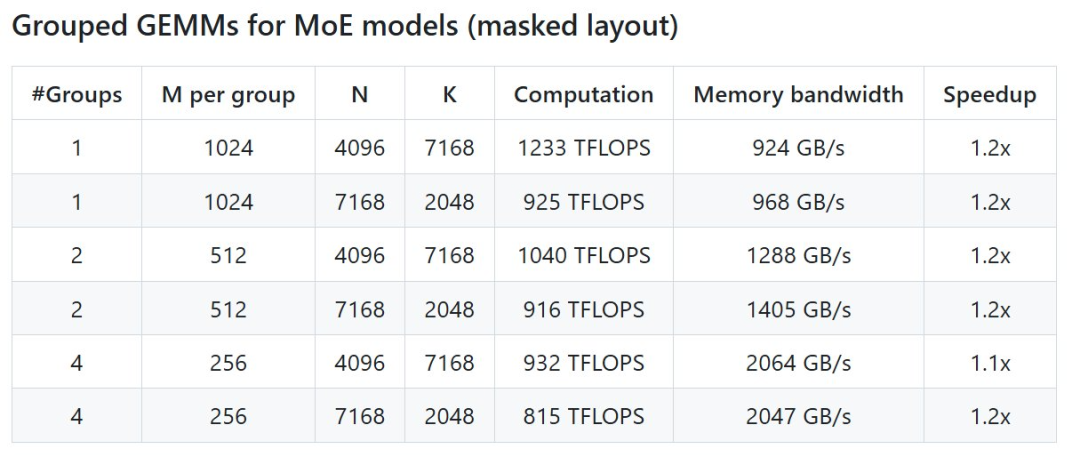
DeepSeek 在 H800 上 使用 NVCC 12.8 测试了 DeepSeek-V3/R1 推理中可能 使用的全部 形态(包含预填充和解码,但不包含张量并行),最高 能够实现 2.7 倍加快 。全部加快指标均基于内部精心优化的 CUTLASS 3.6 实现 。
但依据 名目介绍,DeepGEMM 在某些 形态上 体现不佳 。
快捷启动
首先需求这些配置
Hopper 架构的 GPU,必须 支撑 sm_90a;
Python 3.8 或更高版本;
CUDA 12.3 或更高版本,但为了 获得最佳性能,DeepSeek 强烈推举 使用 12.8 或更高版本;
PyTorch 2.1 或更高版本;
CUTLASS 3.6 或更高版本(可通过 Git 子模块克隆) 。
配置 实现后,便是部署:
# Submodule must be cloned
git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git
# Make symbolic links for third-party (CUTLASS and CuTe) include directories
python setup.py develop
# Test JIT compilation
python tests/test_jit.py
# Test all GEMM implements (normal, contiguous-grouped and masked-grouped)
python tests/test_core.py
而后是安装:
python setup.py install
最终在你的 Python 名目中导入 deep_gem,就 能够 使用了 。
更多信息请参见 GitHub 开源库 。
路透社:DeepSeek R2 大模型又提前了,5 月之前公布
就在 DeepSeek 紧锣密鼓地开源的同时,人们也在 到处探寻该公司下一代大模型的信息 。昨天晚上,路透社蓦地爆料说 DeepSeek 可能会在 5 月之前公布下一代 R2 模型,激发了关注 。

据多位知情人士 透露,DeepSeek 正在加快推出 R1 强推理大模型的后续版本 。其中有两人 示意,DeepSeek 原本 方案在 5 月初公布 R2,但现在 指望尽早公布 。DeepSeek 指望新模型 占有更 壮大的代码生成 威力,并 能够推理除英语以外的语言 。
可见在 Grok 3、Claude 3.7、Qwen 2.5-Max 等竞品面世之后,DeepSeek 又加快了技术演进的 步调 。
值得一提的是,媒体也介绍了该公司的一些状况 。DeepSeek 在北京开设的办公室 间隔清华、北大很近(步行可至) 。据两名前员工称,梁文锋 时常会与工程师们 深刻探究技术细节,并乐于与实习生、应届毕业生一同工作 。他们还 形容了通常在 合作 空气中天天工作八小时的状况 。
据三位了解 DeepSeek 薪酬状况的人士称,这幻方量化与 DeepSeek 都以薪酬 丰富而闻名 。有人 示意在幻方的高级数据科学家年薪 150 万元人民币并不 罕见,而竞争对手的薪酬很少超过 80 万元 。
幻方是 AI 交易的早期先驱,一位该公司高管早在 2020 年 示意将「All in」人工智能,将公司 70% 的收入投资于人工智能探究 。该公司在 2020 年和 2021 年斥资 12 亿元人民币建设了两个超级计算 AI 集群 。第二个集群 Fire-Flyer II 由约一万块英伟达 A100 芯片构成,重要用于训练 AI 模型 。
在 DeepSeek V3、R1 模型推出之后,全世界关于 AI 技术的等待已经进入了高点 。科技公司都在消化 DeepSeek 提出的新技术, 批改进展方向,用户们则纷纷开始尝试各类生成式 AI 利用 。
兴许下一次 DeepSeek 的公布,会是 AI 行业的再一次 要害时刻 。



