Meta 工程师自曝疯狂熬夜复制 DeepSeek,天价高管也心虚 |
|
珠江路在线
2025年1月24日
【
转载
】日本动漫
|
|
|
Meta 员工在 TeamBlind 爆料,点燃了一把火 。 自夸开源先锋的 Meta,直接被 DeepSeek 这家中国公司整得 汗颜无地 。不只工程师争分夺秒复现模型,年薪超过 DeepSeek 训练成本的高管们,心底也有点虚 。

今日,Meta 员工在匿名社区 TeamBlind 上的一个帖子,在业内被传疯了 。
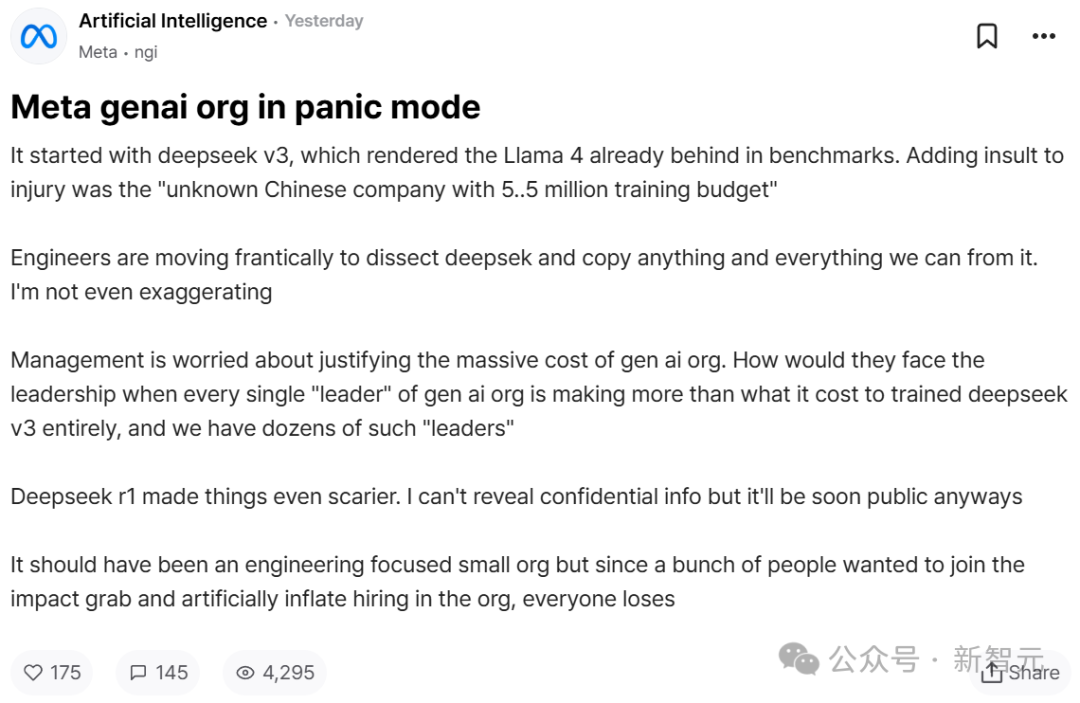
DeepSeek, 实在地给了美国人亿点点「震撼」 。
DeepSeek R1 是世界上首个与 OpenAI o1 比肩的 AI 模型,并且与 o1 不同,R1 还是开源模型「Open Source Model」,比 OpenAI 还 Open!
更有人曝料,DeepSeek 还只不过个「副 名目」,主业 根本不是搞大模型!
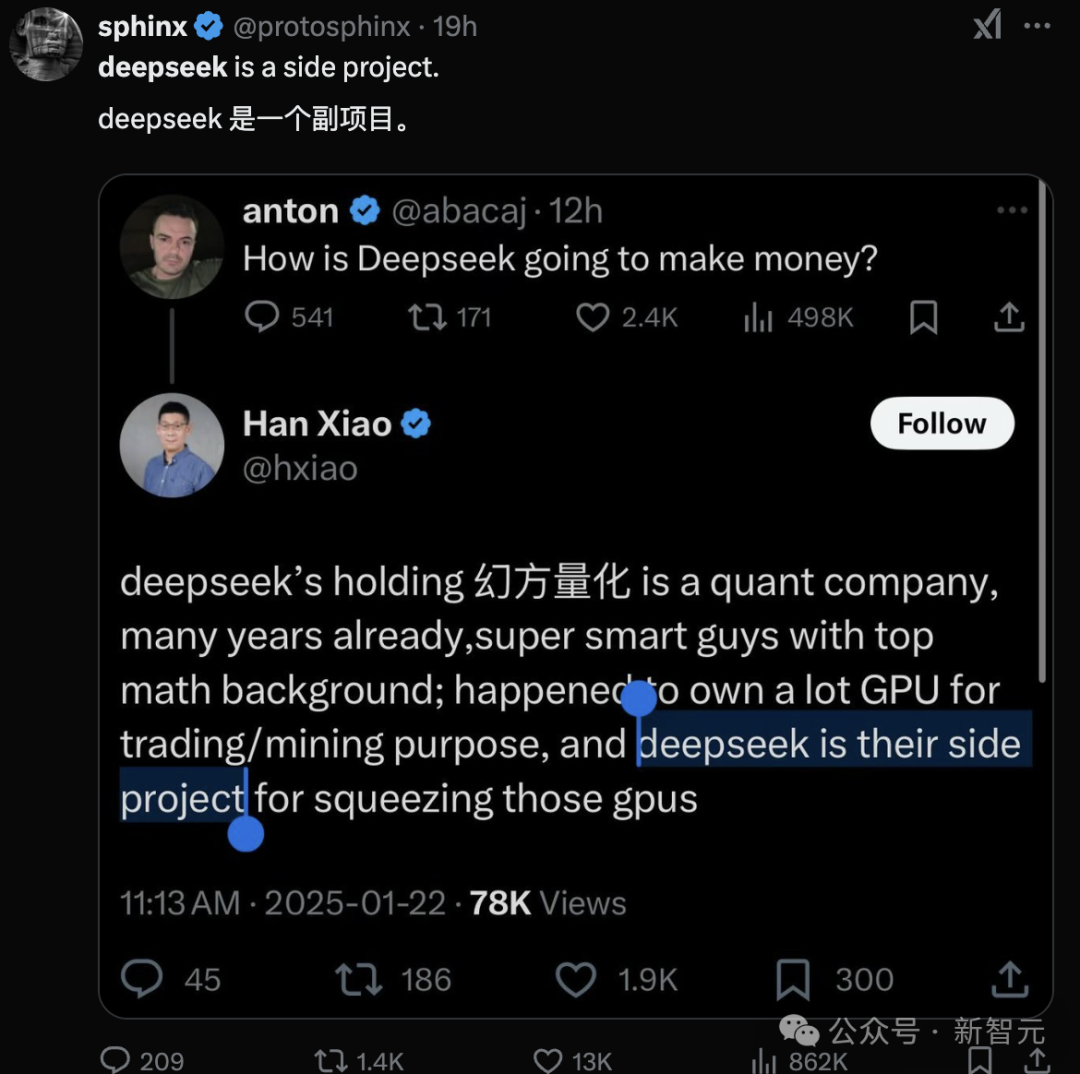
这不,OpenAI 还没慌呢,Meta 先慌了!
毕竟 Meta 向来 自夸开源先锋,但 DeepSeek 这种程度的开源,直接把它们拍在沙滩上 。
更可怕的是,DeepSeek 的成本也太太太低了,这么比起来,Meta 拿着超高 估算的团队,就显得很 难堪 。
那些一个人拿的薪资,就超过整个 DeepSeek V3 训练成本(仅 550 万美元)的高管,尤其 坐立不安 。

依据内部 Meta 内部人士爆料,DeepSeek 上一年的 V3,已经给他们压力了 。
现在,Meta 的工程师正在 松开 所有 工夫,争分夺秒地 综合 DeepSeek,试图复制其中 所有可能的技术 。
以往,是全世界追着美国的大模型拿着放大镜探究,现在状况竟倒转了过来,美国人也开始逆向工程了 。今夕是何夕?
中国大模型的狂飙猛进,真的让我们感到了魔幻 事实主义的滋味 。
Meta 工程师吓疯了
TeamBlind 上的帖子,全文曝料如下:
所有源于 DeepSeek V3 的浮现,它在基准测试中已经让 Llama 4 黯然失色 。更让人难堪的是,一家「仅用 550 万美元训练 估算的中国公司」就做到了这丝毫 。
工程师们正在争分夺秒地 综合 DeepSeek,试图复制其中的 所有可能技术 。这绝非 夸大 。
治理层正为如何 证实 GenAI 研发部门的巨额投入而发愁 。当部门里一个高管的薪资就超过训练整个 DeepSeek V3 的成本,并且这样的高管还有数十位,他们该如何向高层交代?
DeepSeek R1 的浮现让状况更加严重 。具体细节属于 机密,不便 透露,不过很快就会公开了 。
这本该是一个以工程为导向的精简部门,但由于太多人想要分一杯羹,人为膨胀 应聘规模,最后招致人人都付出了代价 。
在成本上,「一个高管 = DeepSeek V3」,这对给高管们开出天价年薪的硅谷大厂们, 着实是啪啪打脸 。

更是有网友被震惊到:「DeepSeek R1 在 OpenAI、Meta、Grok 以及谷歌的屁股下点了一把火,就像 Open AI 在第一次推出 ChatGPT 时那样震撼 。假如去掉人力瓶颈,达到 o1 级性能真的不需求花太多钱!!」

有网友认为,在这次 AI 浪潮中,Meta 确实落后了 。
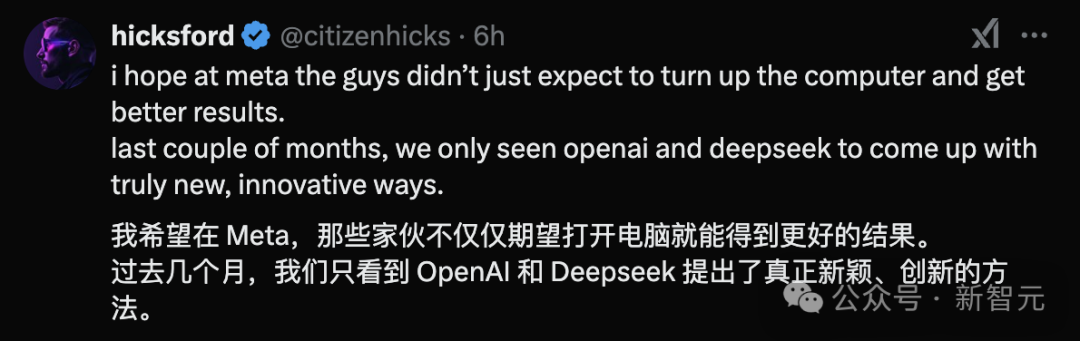
但也有网友为 Meta 解释,毕竟 Meta 已经开始行动了, 固然在 GenAI 领域确实「人浮于事」 。
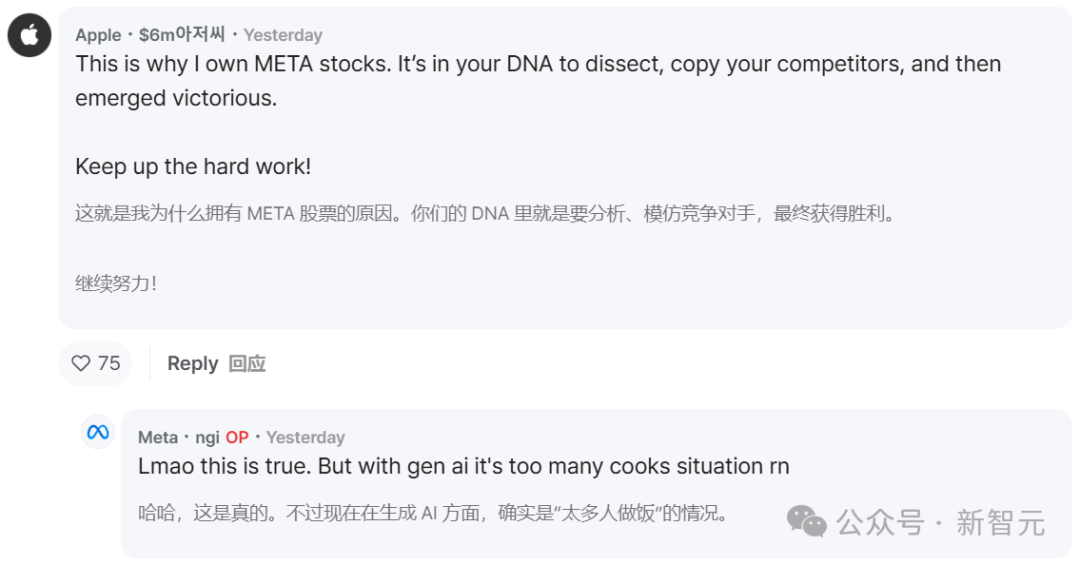
甚至,这个来自中国的 AI 已经上了美国的新闻 。措辞十分 夸大 ――「中国初创企业 DeepSeek, 要挟了美国 AI 的主导地位 。」
「 否定、愤慨、无望、 承受,美国人正在进行困难的心理重建 。这是他们历史上从未见过的最强对手 。」
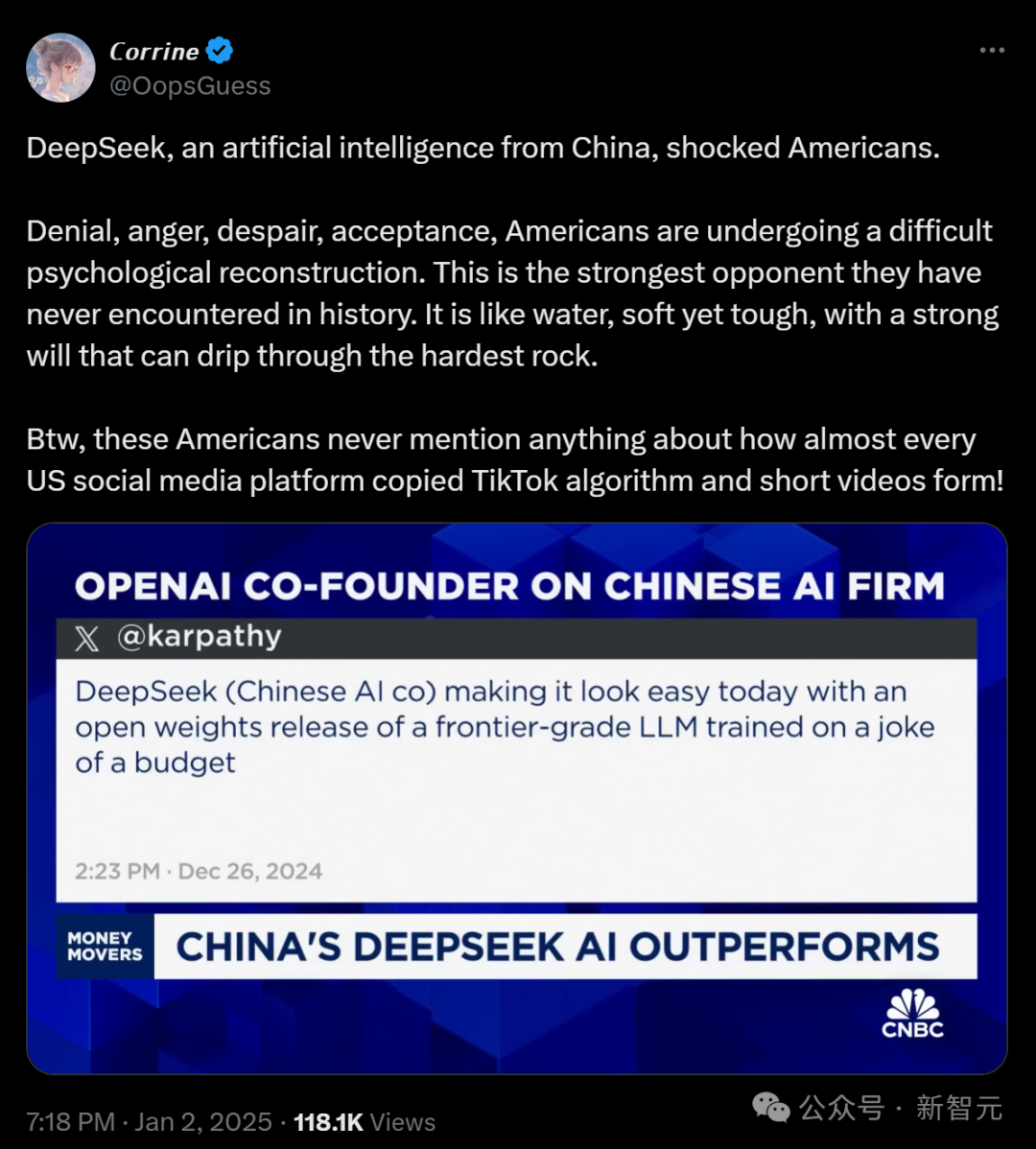
不到 600 万美元的成本,就能训出一个如此强的模型,这 几乎是彻底扯掉了美国金融业的遮羞布 。AI 产业,真的需求动不动数万亿美元的投资么?
连带着,特朗普和阿尔特曼搞的 5000 亿美元星际之门,也一下子变得可疑了起来 。
DeepSeek-R1 有多强?
「花小钱办大事」,可见 DeepSeek 团队确实有「独门秘籍」,在技术上恐怕也 超过了 OpenAI 。
DeepSeek 还发表了 有关论文,介绍了 DeepSeek-R1 的大规模强化学习(RL)训练、未 通过监督微调(SFT)作为预 解决步骤等技术细节 。
 论文链接:https://arxiV.org/ pdf/2501.12948
论文链接:https://arxiV.org/ pdf/2501.12948这种「技术自信」,让 部分美国网友都开始了「反思」 。

为什么 AI 圈,如此 害怕 DeepSeek?
来自 VB 最新一篇独家文章,特意将 AI 界黑马 DeepSeek 激发 AI 界 轰动做了全面 综合 。

就在几天前,惟独最专业的极客们才据说过 DeepSeek 。
它是一家成立于 2015 年幻方量化公司,背后投资者 High-Flyer Capital Management 。
直到过去几天,这家公司迅速成为硅谷最受关注的颠覆者,这重要归功于 DeepSeek R1 的诞生 。
不用 SFT,仅凭强化学习就让模型推理性能堪比 o1,并且在多项基准测试中,R1 甚至 超过了 o1 。
令人瞠目结舌的是,如此 壮大的模型,训练成本仅 500 万美金, 使用的 GPU 数量也远远低于 OpenAI 。
不只如此,他们直接将其开源,Hugging Face 下载量和活跃度直接爆表 。
并且,开发者 能够 自由微调训练,API 成本要比 等同 o1 模型低 90% 还要多 。
与 OpenAI 仅低性能模型上提供网页查找不同,DeepSeek 直接将 R1 与查找 性能深度整合 。
在一步一步策略中,这家中国公司完胜了 OpenAI 。
第一个,但不是最后一个
这也不会是最后一个, 挑战硅谷巨头主导地位的中国 AI 模型 。
近期,字节崭新公布了「豆包 1.5 Pro」,在第三方基准测试中,其性能与 GPT-4o 模型相当,但成本仅为后者的 1/50 。
中国模型的 快捷迭代,已经引起国际关注:
《经济学人》杂志方才发表了一篇对于 DeepSeek 顺利以及 其余中国企业的 顺利 。

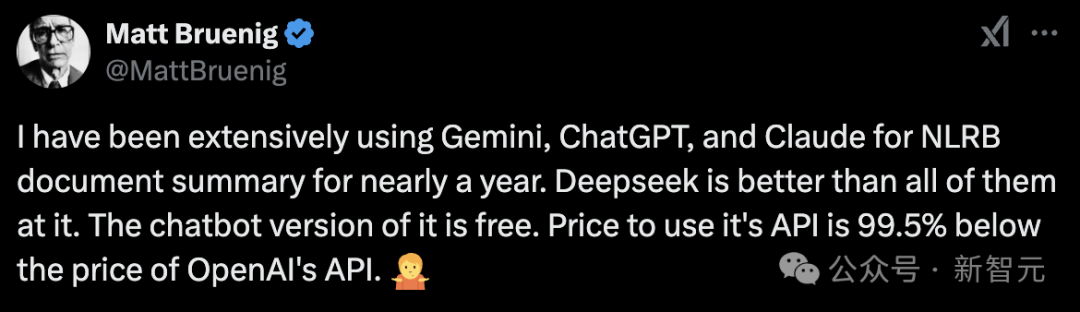
政治评论员 Matt Bruenig 的实际体验,也更加印证了中国 AI 模型的实力 。
最后一句话总结:中国 AI 崛起了,美国还得适应 。



