如何调优SQL Server查询 |
|
在今天的文章里,我想给你展示下,当你想对特定查询创建索引设计时,如何把你的工作和思考过程传达给查询优化器 。下面就一起来探讨一下吧! 有问题的查询 DECLARE @i INT = 999 SELECT SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, LineTotal FROM Sales.SalesOrderDetail WHERE ProductID < @i ORDER BY CarrierTrackingNumber GO 如你所见,这里用了一个本地变量与一个不等于谓语来从Sales.SalesOrderDetail表来获取一些记录 。当你执行那个查询,看它的执行计划时,你会发现它有一些严重的问题:
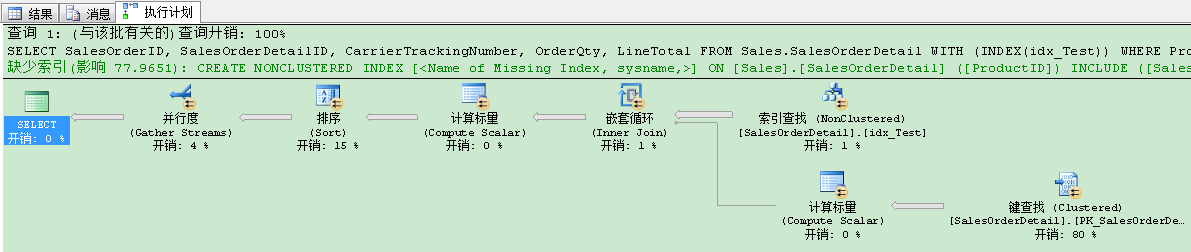
现在我问你――你能改善这个查询么?你的建议是什么?休息下,想个几分钟 。不修改查询本身,你如何改善这个查询? 我们来调试查询! WHERE ProductID < @i 我们请求在ProductID列过滤的行 。因此我们想在那个列创建支持的非聚集索引 。我们建立索引: CREATE NONCLUSTERED INDEX idx_Test ON Sales.SalesOrderDetail(ProductID) GO 在非聚集索引创建后,我们需要验证下改变,因此我们再次执行刚才的查询代码 。结果如何捏?查询优化器并没有使用我们刚创建的非聚集索引!我们在搜索谓语上创建了支持的非聚集索引,查询优化器没有引用它?通常人们对此就无辙了 。其实我们可以提示查询优化器来使用非聚集索引,来更好的理解“为什么”查询优化器没有自动选择索引: DECLARE @i INT = 999 SELECT SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, LineTotal FROM Sales.SalesOrderDetail WITH (INDEX(idx_Test)) WHERE ProductID < @i ORDER BY CarrierTrackingNumber GO 当你现在看执行计划时,你会看到下列的野性――一个并行计划:
查询花费了370109个逻辑读!运行时间基本和刚才的一样 。这里到底发生了什么?当你仔细看执行计划,你会发现查询优化器引入了书签查找,因为刚才创建的非聚集索引,对于查询来说,不是一个覆盖非聚集索引 。查询越过了所谓的临界点(Tipping Point),因为我们用当前的搜索谓语来获得几乎所有行 。因此用非聚集索引和书签查找来组合没有意义 。 不去想为什么查询优化器不选择刚才创建的非聚集索引,我们已经把自己的思路表达给了查询优化器本身,通过查询提示进行了询问了查询优化器,为什么非聚集索引没被自动选择 。如我刚开始说的:我不想考虑太多 。 使用非聚集索引解决这个问题,在非聚集索引的叶子层,我们必须对从SELECT列表的请求的额外列进行包含 。你可以再次看下书签查找来看下在叶子层哪些列当前丢失:
我们重建那个非聚集索引: CREATE NONCLUSTERED INDEX idx_Test ON Sales.SalesOrderDetail(ProductID) INCLUDE (CarrierTrackingNumber, OrderQty, UnitPrice, UnitPriceDiscount) WITH ( DROP_EXISTING = ON ) GO
我们已经做出了另1个改变,因此我们可以重新运行了查询来验证下 。但是这次我们不加查询提示,因为现在查询优化器会自动选择非聚集索引 。结果如何捏?当你看执行计划时,索引现在已被选择 。
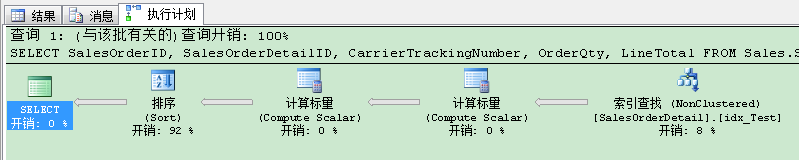
SQL Server现在在非聚集索引上进行了查找操作,但在执行计划里我们还有排序(Sort)运算符 。因为基数计算30%的硬编码,排序(Sort)还是要蔓延到TempDb 。偶滴神!我们的逻辑读已经降到了757,但运行时间还是近800毫秒 。你现在应该怎么做? 现在我们可以尝试在非聚集索引的导航结构直接包含CarrierTrackingNumber列 。这是SQL Server进行排序运算符的列 。当我们在非聚集索引直接加了这列(作为主键),我们就物理排序了那列,因此排序(Sort)运算符应该会消失 。作为积极的副作用,也不会蔓延到TempDb 。在执行计划里,现在也没有运算符关心错误的基数计算 。因此我们尝试那个假设,再次重建非聚集索引: CREATE NONCLUSTERED INDEX idx_Test ON Sales.SalesOrderDetail(CarrierTrackingNumber, ProductID) INCLUDE (OrderQty, UnitPrice, UnitPriceDiscount) WITH ( DROP_EXISTING = ON ) GO 从索引定义可以看到,现在我们已经对CarrierTrackingNumber和ProductID列的数据物理预排序 。当你再次重新执行查询,在你查看执行计划时,你会看到排序(Sort)运算符已经消失,SQL Server扫描了非聚集索引的整个叶子层(使用剩余谓语(residual predicate)作为搜索谓语) 。
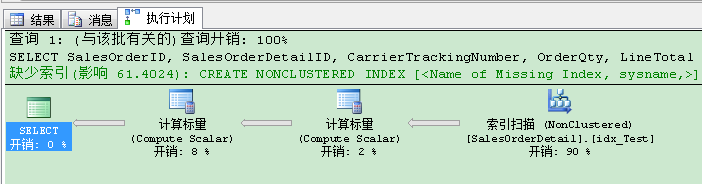
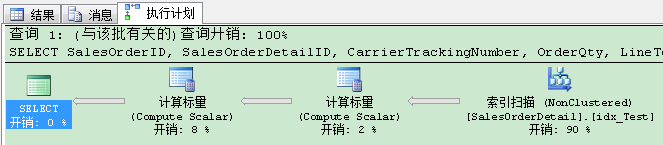
这个执行计划并不坏!我们只需要763个逻辑读,现在的运行时间已经降至600毫秒 。和刚才的相比已经有25%的改善!但是:查询优化器建议我们一个更好的非聚集索引,通过缺少索引建议(Missing Index Recommendations)!暂且相信下,我们创建建议的非聚集索引: CREATE NONCLUSTERED INDEX [SQL Server doesnt care about names, why I should care about names?] ON [Sales].[SalesOrderDetail] ([ProductID]) INCLUDE ([SalesOrderID],[SalesOrderDetailID],[CarrierTrackingNumber],[OrderQty],[LineTotal]) GO 当你现在重新执行最初的查询,你会发现令人惊讶的事情:查询优化器使用“我们”刚才创建的非聚集索引,缺少索引建议已经消失!
你刚刚创建了SQL Server从不使用的索引――除了INSERT,UPDATE和DELETE语句,SQL Server都要去维护你的非聚集索引 。对于你的数据库,你刚创建了“单纯”浪费空间的索引 。当另一方面,你已经通过消除丢失索引建议,满足了查询优化器 。但这不是目的:目的是创建会被再次使用的索引 。 结论:永不相信查询优化器! 小结 今天的文章有点争议性,但我想你向你展示下,但你在创建索引时,查询优化器如何帮助你,还有查询优化器如何愚弄你 。因此做出小的调整,就立即运行你的查询,验证改变非常重要 。 以上就是本文的全部内容,希望对大家的学习有所帮助 。 |