Oracle9i 数据库设计指引全集 |
||||||||
|
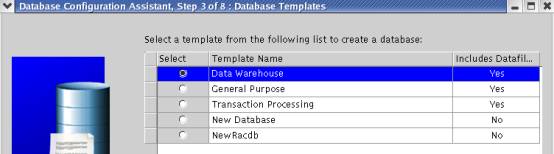
1.2.3 数据库类型选择
对于海量数据库系统,采用data warehouse的类型。对于小型数据库或OLTP类型的数据库,采用Transaction Processing类型。
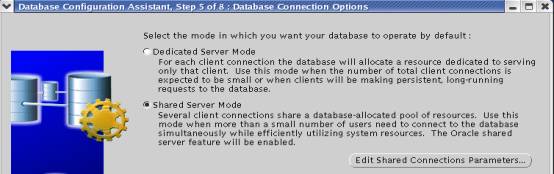
1.2.4 数据库连接类型选择
Oracle数据库有专用服务器连接类型和多线程服务器MTS连接类型。对于批处理服务,需要专用服务器连接方式,而对于OLTP服务则MTS的连接方式比较合适。由于采用MTS后,可以通过配置网络服务实现某些特定批处理服务采用专用服务器连接方式,所以数据库设计时一般采用MTS类型。
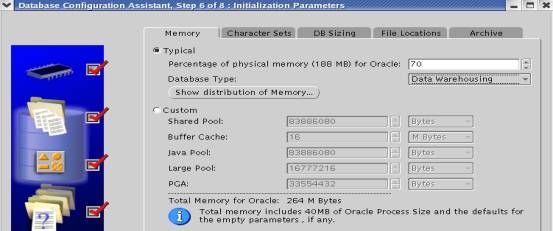
1.2.5 数据库SGA配置
数据库SGA可以采用手工配置或按物理内存比例配置,在数据库初始设计阶段采用按比例配置方式,在实际应用中按系统调优方式修改SGA。
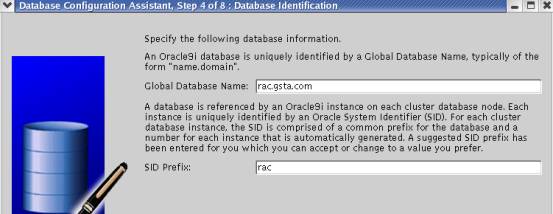
1.2.6 数据库字符集选择
为了使数据库能够正确支持多国语言,必须配置合适的数据库字符集,采用UTF8字符集。
注意:如果没有大对象,在使用过程中进行语言转换没有什么影响,具体过程如下(切记设定的字符集必须是ORACLE支持,不然不能start)
1.2.7 数据库其他参数配置
1.2.7.1 DB_FILES
Db_files是数据库能够同时打开的文件数量,默认值是200个。当数据库规划时文件数量FILES接近或超过200个时候,按以下估计值配置:
1.2.7.2 Db_block_size
一个extent要是5个blocks的倍数为好,如:一个blocks是4096字节,那一个extent就是2M、4M或8M为好。Db_block_size是数据库最小物理单元,一旦数据库创建完成,该参数无法修改,db_block_size按以下规则调整:
数据仓库类型: db_block_size尽可能大,采用8192 或 16384
OLTP类型: db_block_size 用比较小的取值范围: 2048 或 4096
Blocks推荐是系统操作的块倍数(裸设备块大小是512字节,NTFS是 4K,使用8K的方式在大部分系统上通用)。
1.2.8 数据库控制文件配置
1.2.8.1 控制文件镜象
多个控制文件存放在不同的物理位置。
1.2.8.2 控制文件配置
控制文件中参数设置,最大的数据文件数量不能小于数据库参数db_files。
1.2.9 数据库日志文件配置
1.2.9.1 日志文件大小
日志文件的大小由数据库事务处理量决定,在设计过程中,确保每20分钟切换一个日志文件。所以对于批处理系统,日志文件大小为几百M 到几G的大小。对于OLTP系统,日志文件大小为几百M以内。
1.2.9.2 日志文件组数量
对于批处理系统,日志文件组为5―10组;对于OLTP系统,日志文件组为 3―5组,每组日志大小保持一致;对于集群数据库系统,每节点有各自独立的日志组。
1.2.9.3 日志成员数量
为了确保日志能够镜象作用,每日志组的成员为2个。
1.2.10 数据库回滚段配置
在Oracle9i数据库中,设计Undo表空间取代以前版本的回滚段表空间。
Undo 表空间大小的设计规范由以下公式计算:
Undospace = UR * UPS *db_block_size+ 冗余量
UR: 表示在undo中保持的最长时间数(秒),由数据库参数UNDO_RETENTION值决定。
UPS:表示在undo中,每秒产生的数据库块数量。
例如:在数据库中保留2小时的回退数据,假定每小时产生200个数据库块。则Undospace = 2 * 3600 * 200 * 4K = 5.8G
1.2.11 数据库临时段表空间配置
数据库临时段表空间根据实际生产环境情况调整其大小,表空间属性为自动扩展。
1.2.12 数据库系统表空间配置
系统表空间大小1G左右,除了存放数据库数据字典的数据外,其他数据不得存储在系统表空间。
1.3 数据库表空间设计原则
1.3.1 表空间大小定义原则
当表空间 大小小于操作系统对最大文件限制时,表空间由一个文件组成。如果表空间大小大于操作系统对最大文件限制时,该表空间由多个数据文件组成,表空间的总大小为估算为:
Tablespace + sum (数据段+索引段)*150%。
1.3.2 表空间扩展性设计原则 1.4 裸设备的使用
一个scsi设备可以 14个分区,unix操作系统256个分区,性能比文件系统方式高15%左右,空间大于要小于(实际分区大小减两个ORACLE的数据块),比如100M,大于为100000K,推荐在unix使用软连接(ln)方式把裸设备形成文件,用加入表空间时加resue 选项,当然也可只接把设备加入表空间,移动裸设备使用dd命令
对于windows平台,oracle提供软连接工具,实现裸设备的使用,计算一条记录的长度
2 数据库逻辑设计原则
2.1 命名规范
2.1.1 表属性规范
2.1.1.1 表名
前缀为Tbl_ 。数据表名称必须以有特征含义的单词或缩写组成,中间可以用“_”分割,例如:tbl_pstn_detail。表名称不能用双引号包含。
2.1.1.2 表分区名
前缀为p 。分区名必须有特定含义的单词或字串。
例如 :tbl_pstn_detail 的分区p2004100101表示该分区存储 2004100101时段的数据。
2.1.1.3 字段名
字段名称必须用字母开头,采用有特征含义的单词或缩写,不能用双引号包含。
2.1.1.4 主键名
前缀为PK_。主键名称应是 前缀+表名+构成的字段名。如果复合主键的构成字段较多,则只包含第一个字段。表名可以去掉前缀。
2.1.1.5 外键名
前缀为FK_。外键名称应是 前缀+ 外键表名 + 主键表名 + 外键表构成的字段名。表名可以去掉前缀。
2.1.2 索引
4.1.2.1 普通索引
前缀为IDX_。索引名称应是 前缀+表名+构成的字段名。如果复合索引的构成字段较多,则只包含第一个字段,并添加序号。表名可以去掉前缀。
2.1.2.2 主键索引
前缀为IDX_PK_。索引名称应是 前缀+表名+构成的主键字段名,在创建表时候用using index指定主键索引属性。
2.1.2.3 唯一所以
前缀为IDX_UK_。索引名称应是 前缀+表名+构成的字段名。
2.1.2.4 外键索引
前缀为IDX_FK_。索引名称应是 前缀+表名+构成的外键字段名。
2.1.2.5 函数索引
前缀为IDX_func_。索引名称应是 前缀+表名+构成的特征表达字符。
2.1.2.6 蔟索引
前缀为IDX_clu_。索引名称应是 前缀+表名+构成的簇字段。
2.1.3 视图
前缀为V_。按业务操作命名视图。
2.1.4 实体化视图
前缀为MV_。按业务操作命名实体化视图。
2.1.5 存储过程
前缀为Proc_ 。按业务操作命名存储过程
2.1.6 触发器
前缀为Trig_ 。触发器名应是 前缀 + 表名 + 触发器名。
2.1.7 函数
前缀为Func_ 。按业务操作命名函数
2.1.8 数据包
前缀为Pkg_ 。按业务操作集合命名数据包。
2.1.9 序列
前缀为Seq_ 。按业务属性命名。
2.1.10 表空间
2.1.10.1 公用表空间
前缀为Tbs_ 。 根据存储的特性命名,例如: tbs_parameter 。
2.1.10.2 专用表空间
Tbs_<表名称>_nn。该表空间专门存储指定的某一个表,或某一表的若干个分区的数据
2.1.11 数据文件
<表空间名>nn.dbf 。nn =1,2,3,4,…等。
2.1.12 普通变量
前缀为Var_ 。 存放字符、数字、日期型变量。
2.1.13 游标变量
前缀为Cur_ 。存放游标记录集。
2.1.14 记录型变量
前缀为Rec_ 。 存放记录型数据。
2.1.15 表类型变量
前缀为Tab_ 。 存放表类型数据。
2.1.16 数据库链
前缀为dbl_ 。 表示分布式数据库外部链接关系。
2.2 命名
2.2.1 语言
命名应该使用英文单词,避免使用拼音,特别不应该使用拼音简写。命名不允许使用中文或者特殊字符。
英文单词使用用对象本身意义相对或相近的单词。选择最简单或最通用的单词。不能使用毫不相干的单词来命名
当一个单词不能表达对象含义时,用词组组合,如果组合太长时,采用用简或缩写,缩写要基本能表达原单词的意义。
当出现对象名重名时,是不同类型对象时,加类型前缀或后缀以示区别。
2.2.2 大小写
名称一律大写,以方便不同数据库移植,以及避免程序调用问题。
2.2.3 单词分隔
命名的各单词之间可以使用下划线进行分隔。
2.2.4 保留字
命名不允许使用SQL保留字。
2.2.5 命名长度
表名、字段名、视图名长度应限制在20个字符内(含前缀)。
2.2.6 字段名称
同一个字段名在一个数据库中只能代表一个意思。比如telephone在一个表中代表“电话号码”的意思,在另外一个表中就不能代表“手机号码”的意思。
不同的表用于相同内容的字段应该采用同样的名称,字段类型定义。
2.3 数据类型
2.3.1 字符型
固定长度的字串类型采用char,长度不固定的字串类型采用varchar。避免在长度不固定的情况下采用char类型。如果在数据迁移等出现以上情况,则必须使用trim()函数截去字串后的空格。
2.3.2 数字型
数字型字段尽量采用number类型。
2.3.3 日期和时间
2.3.3.1 系统时间
由数据库产生的系统时间首选数据库的日期型,如DATE类型。
2.3.3.2 外部时间
由数据导入或外部应用程序产生的日期时间类型采用varchar类型,数据格式采用:YYYYMMDDHH24MISS。
2.3.3.3 大字段
如无特别需要,避免使用大字段(blob,clob,long,text,image等)。
2.3.3.4 唯一键
对于数字型唯一键值,尽可能用系列sequence产生。
2.4 设计
2.4.1 范式
如无性能上的必须原因,应该使用关系数据库理论,达到较高的范式,避免数据冗余,但是如果在数据量上与性能上无特别要求,考虑到实现的方便性可以有适当的数据冗余,但基本上要达到3NF.如非确实必要,避免一个字段中存储多个标志的做法。如11101表示5个标志的一种取值。这往往是增加复杂度,降低性能的地方。
2.5.5 安全性
2.5.5.1 Where 条件
无论在使用Select,还是使用破坏力极大的Update和Delete语句时,一定要检查Where条件判断的完整性,不要在运行时出现数据的重大丢失。如果不确定,最好先用Select语句带上相同条件来果一下结果集,来检验条件是否正确。
2.5.6 完整性
有依赖关系的表,例如主外键关系表,在删除父表时必须级联删除其子表相应数据,或则按照某种业务规则转移该数据。9I中表中字段缩小及变类型,字段为空或表空,varchar和char长度不变可任意改,字段名和表名可字段可用 ALTER TABLE table SET UNUSED (column) 设定为不可用,注意无命令再设为可用
3 备份恢复设计原则
3.1 数据库exp/imp备份恢复
Oracle数据库的Exp、Imp提供了数据快速的备份和恢复手段,提供了数据库级、用户级和表级的数据备份恢复方式。这种方法一般作为数据库辅助备份手段。
3.1.1 数据库级备份原则
在数据库的数据量比较小,或数据库初始建立的情况下采用。不适合7*24的在线生产环境数据库备份。
3.1.2 用户级备份原则
在用户对象表数据容量比较小、或则用户对象初始建立的情况下使用。
3.1.3 表级备份原则
主要在以下场合采用的备份方式:
参数表备份
静态表备份
分区表的分区备份。
3.2 数据库冷备份原则
数据库冷备份必须符合以下原则:
数据库容量比较小。
数据库允许关闭的情况。
3.3 Rman备份恢复原则
这种方式适用于7*24环境下的联机热备份情形。
3.3.1 Catalog数据库
单独建立备份恢复用的数据库实例,尽可能与生产环境的数据库分开,确保catalog与生产数据库的网络连接良好。在9I系统使用良好的备份策略以可,支持完全使用控制文件保存catalog信息,备份策略如下:
注意:对数据库设定控制文件保存备份信息为365天,具体语句如下。
3.3.2 Archive Log
设置Archive Log 的位置,确保存储介质有足够的空间来保留指定时间内archive log的总量。建设定期对RMAN进行全备份,删除冗余归档日志文件。
3.3.3 全备份策略
对于小容量数据库,可以采用全备份策略。对于大容量数据库,必须制定全备份策略方案,备份时对archive log进行转储,同时冷备份catalog 数据库。
3.3.4 增量备份策略
对于大容量数据库,必须制定增量备份、累积备份和全备份的周期,备份时对archive log进行转储,同时冷备份catalog 数据库。
3.3.5 恢复原则
采用Rman脚本进行数据库恢复。数据库恢复有以下几种:
3.3.5.1 局部恢复
主要用于恢复表空间、数据文件,一般不影响数据库其他操作。
3.3.5.2 完全恢复
数据库恢复到故障点,由catalog当前数据库决定。
3.3.5.3 不完全恢复
恢复到数据库的某一时间点或备份点。
恢复catalog数据库。
恢复数据库control file 。
恢复到数据库某一时间点。
重设日志序列。
3.4 备用数据库原则
数据库系统在以下情况下可以考虑采用备用数据库data guard原则:
数据库容量适中。
数据库严格要求7*24不间断,或间断时间要求控制在最小范围内。
数据库要求有异地备份冗余。
3.5 一些小经验
使用oemc的oms时,首选项要求是节点和数据库分别加入系统用户(如:administrator)和数据库DBA用户(system)。节点的系统用户必须有批处理作业登录的权限
agent 不能启动,lisnter修改后都要手动删除oracle\ora9\network\agent 中的*.q文件
oracle\admin\my9i\bdump 中是用户的出错日志
改变表的空间的方式alter table hr.ssss move TABLESPACE example(要重建索引); 或用imp导入时,设定导入用户只有某一表空间的使用权,无RESOURCE角色和UNLIMITED TABLESPACE权限
aleter system set log_checkpoint_to_alter=true,后可报警文件发现checkpoint的起动和结束时间。
3.6 系统调优知识
3.6.1.1 生成状态报表(statspack的使用)
使用(存放位置@?\rdbms\admin\)的文件生成报表用户
@?\rdbms\admin\Spcreate.sql建表
将timed_statistics设定true
使用生成的perfstat用户登录,执行以下语句手动收集信息
Exex statspack.snap
Exec statspack.snap(I_SNAP_LEVEL=>0,I_MODEFY_PRAMETER=>TRUE) 0级,最少10最大
使用下面的语句生成状态报表
@?\rdbms\admin\Spreport.sql
其他相关文件
delete stats$snapshot ;清原来记录数据
@?\rdbms\admin\Saputo.sql
select job from user_jobs 取用户作业号
exec dbms_remove(作业号)
timed_statistics=true要求
@?\rdbms\admin\spdrop.sql ;
3.6.1.2 sql追踪
设定全部用户跟踪
alter system set sql_trace=true;
用户级别跟踪
alter session set sql_trace=true;
用户的跟踪文件生成在 admin\{pid}\udump\{pid} _ora_{ SPID}.trc 中,spid从下面语句得到
SELECT b.name bkpr, s.username, p.spid,s.sid,s.serial# FROM v$bgprocess b, v$session s, v$process p WHERE p.addr = b.paddr(+) AND p.addr = s.paddr and s.username=user;
DBA对特定用户跟踪
exec dbms_system_set_Sql_trace_in_session(sid,serial#,true)
信息从下面得到
SELECT b.name bkpr, s.username, p.spid,s.sid,s.serial#,osuser,s.program
FROM v$bgprocess b, v$session s, v$process p
WHERE p.addr = b.paddr(+)
AND p.addr = s.paddr;
/*p.spid用于sql_trace时日志编号,dbms_system.set_sql_trace_in_session(sid,erial#,true)*/
用户的跟踪文件生成在 admin\{pid}\udump 中
系统的跟踪文件生成在admin\{pid}\bdump\alert_{pid}.log
tkprof.exe将log文件生成格式化文本
在av Rd(ms) 20以上说明表空间使用过用频繁,考虑将表分开其他表空间上
系统变量fast_start_mttr_target的值要大到不产生log等待,当然也可通过加log组使其不等待
reao log大小应为每30分钟切换一次
建议表空间的利用率不超80%
buffer hit 要达80%以上为好
3.6.1.3 内存调整
一般的内存分配原则
SGA 50%(其中80% DATA BUFFER,15% SHARE POOL,5其他)
PGA30%
OS 20%
例如:2G的WINDOWS的平台,OS 300M,SAG 1.2G,PGA 500M
内存分配的基本单位
SGA《=128M 4M
SGA》128M 64位系统16M,32M系统8M
动态分配时总值不可大于sga_max_size
通过V$SGA_DYNAMIC_FREE_MEMORY取空闲内存空间
在缩小时如果内存空间实际在应用中,CPU利用率将达100%,最后将语句出错。
V$SGASTAT 可看实际的使用情况
Redo log buffer一般在5M内,可通过v$sessuon_wait看是否等,v$sysstat
可也通过报警文件看是否等切换,方法可加组。可通过nologging(数据库也要设定支持nologging)方法减少日志文件产生量。
java_pool 没有设定时,使用shared_pool_size
3.6.1.3.1 shared_pool
本缓冲区用于sql语句,pl sql等的对象保存
Cursor_sharing{Exact|Similar|force} 游标共享设定
Force方式适用OLTP数据库,Exact方式适合数据仓库,similar为智能方式
hard parses 硬SQL语句分析,每秒要底于100次,小要加大shared_pool
soft parse 软SQL语句分析,OLTP要达90%以上,小要加大shared_pool
不建议用无命名PL SQL段
如果有大PL SQL(存储过程)对象可强制保存于内存,也可加大SHARED_POOL_RESERVED_SIZE,大小不可过SHARED_POOL_SIZE的50%,不然实例不能起动
3.6.1.3.2 db_cache
本缓冲区用于数据库数据对象保存
db_cache_advice 为on,可以提出通过企业管理器看到系统建议
通过select * from v$system_event 进行系统查看。
发现存在free buffer waits,说明不能将data buffer及时写入data file;
可通过增加加CPU后,加db_writer_processes=CPU数改善。
也可设disk_asynch_io为true,使用异步IO(前提同要操作系统支持)db_writer_processes=1时(只有一个CPU的情况下),也可通加大dbwr_io_slaves来改善。db_writer_processes>1,不可用本功能
调整效果排序:异步IO>CPU>dbwr_io_slaves
Buffer Busy Waits大说明出现IO冲突
Buffer Busy Waits 大 和 dbbock大说明全表扫描多,说明数据不能读入,可加大
db_cache_size来改善.
Undo block大要加大回滚段(手动管理方式,9I默认是自动管理)
undo header 大要加大回滚段(手动管理方式,9I默认是自动管理)
db_cache命中率99%,不是唯一因素,关系是不要出现等待。建议达90%以上。
内存使用建议:
系统可以设三个缓冲区,建表时可设定用那个缓冲区(默认在db_cache_size)
db_cache_size (默认区)
db_keep_cache_size (常访问,小于db_keep_cache_size的10%的表可放于本区)
db_recycle_cache_size (一个事物完成后常时间不再使用,或两倍大小于缓冲区)
3.6.2 排序的优化
9I为专用服务器时系统变量workarea_size_policy 设定为auto, statistics_level设定为 TYPICAL 可获取v$pga_target_advice中的优化建议。参数pga_aggregate_target值为所有连接用户可用排序内存。
9I为共享服务器时workarea_size_policy设定为menaul, sort_area_size值为每用户排序内存。
如果内存不足将使用TEMP表空间进行排序,排序使用比率disk/meme应小于5%
尽量少用排序,如果使用排序功能,尽量在字段上加索引进行优化。
SQL分析模式:RBO(基于规则)方案小表(驱动表)放在最后,优先使用索引,对SQL语句要求严格(8I以前的模式);CBO (基于开销)根据统计值进行选择开销最少,性能最优的最佳方式进行,但本方式DBA(使用analyze table语句)要定期进行分析统计.系统设定通过optimizer_mode 系统参数
说明: 指定优化程序的行为。如果设置为 RULE, 就会使用基于规则的优化程序, 除非查询含有提示。如果设置为 CHOOSE, 就会使用基于成本的优化程序, 除非语句中的表不包含统计信息。ALL_ROWS 或 FIRST_ROWS
始终使用基于成本的优化程序。
值范围: RULE | CHOOSE | FIRST_ROWS | ALL_ROWS
默认值: CHOOSE
{rule(RBO)|choose(自动选择)|fist_rows| fist_rows_n|all_row}
3.6.3 统计信息
进行某表的统计分析
EXECUTE dbms_stats.gather_table_stats ('HR','EMPLOYEES');
查看结果
4 设计工具
统一使用sybase power designer设计工具,在该工具上完成物理模型的设计。所有的数据库对象尽可能在物理模型上进行设计,而且每个物理模型都要有相应的文字描述。
所有的数据库对象变更以数据库物理模型为基准。为了避免字符敏感问题,产生的脚本以大写字母为标准。
|