用Ultra Search自建超级搜索 |
|||||||
|
Oracle9i数据库的Ultra Search组件能为你的网站提供搜索引擎功能,而且,即使没有软件开发经验的电脑爱好者也可以用不到一天的时间建成自己的搜索引擎。下面就把我制作搜索引擎的全过程展示给大家,下文中所有图片都来自我的搜索引擎实例。 Ultra Search是Oracle公司数据库服务器9i版本的功能组件,是数据库产品的附加功能,它有与其它搜索引擎类似的技术构架,又有自己独到的功能特性。 Ultra Search提供对于四种数据源的基于Web的搜索应用。 1、Web源。 图1为Ultra Search搜索Web站点的情形。 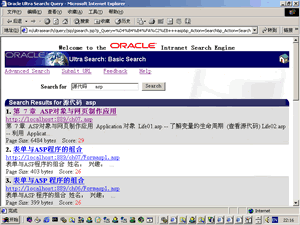 2、文件源。 文件源是指Ultra Search数据库计算机可以访问的文档集,文件类型为包括Word文件在内的150多种常见格式的文件,也包括图形图象文件和视频剪辑。文档集位于本地或远程主机中,这些文档通过文件协议进行索引,可以根据需要创建任意多不同类型的文件源。HTML和纯文本是始终要处理的默认文档类型。图2为Ultra Search对文件服务器搜索的结果,如图所示,已经找到一个类型为"file"的PowerPoint文件。文件源通过file://协议索引,Ultra Search使用Oracle Text过滤器从文档吸取文本和元数据,并自动识别文档类型。如:Microsoft Office Suite 95/97/2000、Spreadsheet documents(如Microsoft Excel、Lotus 1-2-3)、Word 文件(如Microsoft Word 和 Corel Word Perfect)、Acrobat PDF文件、图形表现文件(如Microsoft PowerPoint、Lotus Freehand)等。  3、电子邮件源 电子邮件源代表发送到特定邮件地址的所有邮件,可以将Ultra Search配置为从IMAP服务器搜索电子邮件,这个功能对于搜索发送到邮件列表的邮件特别有用。 4、表源 表源是其内容来源于数据库表的数据源,可创建任意多个新表源,表可来源于多个数据库链接,可以是Oracle数据库或通过ODBC连接的非Oracle数据库,可以实现针对表中列的高级搜索。 Ultra Search是一个全面基于Oracle Text的应用程序,它为Oracle Text用户提供界面友好的Web形式的搜索能力而不需要任何深层的SQL编程,而大量深层技术已被嵌入到转化和调整Web页面查询到底层的基于SQL的Oracle Text查询的过程中。Ultra Search使用对Oracle Text用户来说同样有效的公共接口建立,但增加了相当可观的专门技术在聚集信息的索引、转换查询上,因此有更高质量的查询性能和可扩展的最优化操作。因为Oracle Text与Oracle数据库高度集成,所以实现了Ultra Search自由与动态数据交互。 Ultra Search的组成 Ultra Search由3个组件组成: 1、服务器组件 服务器组件是Oracle9i数据库服务器中的一个组件,它包括:Ultra Search资料库(Ultra Search数据字典、PL/SQL包、Crawler Java类、Ultra Search产品库)、Oracle Text和远程Crawler。 2、Crawler "Crawler"英文本意是爬行动物,而在搜索引擎中它象蜘蛛一样爬行在Internet这张网上,爬行过程就是收集信息并建立索引的过程。 3、中间层组件 中间层组件是Oracle9i数据库服务器的一部分并随着客户端的安装被安装在相同的目录下(可单独定制安装),它包括:管理工具、Java查询应用程序接口、Java电子邮件应用程序接口和JSP查询应用程序。管理工具是JSP页面的Web应用程序,你可以使用它配置和规划数据库实例、数据源、Crawler,管理用户和查询组。Java应用程序接口使用JDBC连接池实现可伸缩性,Java电子邮件应用程序接口用于访问和显示已归档的电子邮件。用户可基于这些接口开发自己的查询应用程序。Ultra Search已经提供一个功能很强的查询应用程序,见图1基础搜索和图2高级搜索,它们基于JSP页面并能工作于任何符合JSP1.0规范的Web服务器引擎。 本文只介绍Ultra Search对Web源和文件源的搜索实现过程。 系统环境为: ● 操作系统:Windows 2000 Advance Server,IIS5.0; ● 数据库:Oracle9.0.1企业版; ● 运行方式:数据库服务器、客户端管理工具和Oracle HTTP Server都运行在同一台主机上。 Oracle9i数据库企业版可从Oracle网站(www.oracle.com免费下载,它已经包含了建设Ultra Search搜索引擎所需要的全部软件组件,另外还需大内存计算机来运行数据库。 如果你的计算机已经安装Oracle9i数据库企业版,则需要设置初始化参数:
不能设置数据库为多线程服务器(MTS),因为它不支持Oracle Text记录。
安装过程很简单,大多数设置已由系统自动实现。如果你的系统没有安装Oracle数据库,你必须使用Oracle通用安装器定制安装数据库,选择Ultra Search功能和数据库客户端管理工具;反之,需要通过数据库配置助手(DBCA)在已经运行的数据库上追加安装Ultra Search功能,并检查客户端管理工具是否完全安装。安装数据库时选择使用数据库中的Oracle HTTP Server作为JSP Web服务器引擎。下文约定:ORACLE_HOME代表Oracle数据库主目录,WEB_ORACLE_HOME代表中间层组件的安装目录,本例中二者相同。 硬件要求: 1、内存要求:大于等于256MB。 2、硬盘空间要求: (1)至少1.4GB硬盘空间安装Oracle9i服务器; (2)相当于物理内存大小的临时表空间; (3)Ultra Search实例的用户表空间需求。要明确建立一个数据库用户作为Ultra Search的实例用户,所有搜索引擎需要的表和索引等数据库对象都存储在这个用户模式下,一般要建立与你将要索引的数据源相同大小的表空间作为Ultra Search实例用户的缺省表空间。 软件要求: Oracle9.0.1企业版。当然附加使用Oracle9i Application Server(9iAS,也可免费下载)可得到更多应用,本例中没采用。 Oracle9i安装过程中,所有Ultra Search文件都被安装到ORACLE_HOME/ultrasearch目录下,数据库用户wksys/wksys被建立,之后需要明确设定下列环境变量(在同一台主机上安装有多个Oracle产品,即有多个Oracle主目录时尤为重要):ORACLE_HOME、ORACLE_SID、PATH(如$ORACLE_HOME/bin:$PATH)、TNS_ADMIN(如network/admin)。 Ultra Search中间层组件的安装及步骤: 本例中中间层组件已随Oracle客户端管理工具被安装,你可以安装中间层组件到多台Web服务器主机上来平衡大量终端用户的查询请求。 1、安装中间层组件,有三个选择: 选项1:安装Ultra Search中间层组件到一个已经安装Oracle HTTP Server的Oracle数据库主目录,那么安装过程可以自动配置中间层组件。为了得到Oracle HTTP Server,在Oracle通用安装器菜单选择"Server"选项,接下来执行定制安装并选择Oracle HTTP Server。 选项2:安装中间层组件到一个不含Oracle HTTP Server的主机,这个选项允许你使用不同的Web服务器。 选项3:使用9iAS作为Web服务器。 安装时,启动Oracle通用安装器,选择Oracle9i Client安装,选择定制选项中的管理工具选项,将安装目录记为$WEB_ORACLE_HOME。 2、配置Web服务器 如果选择选项1,这一步自动进行;如选择选项2,则执行以下几步配置Web服务器。本例选择选项1,但请按以下几步检查: ①把安装中间层组件时键入的安装目录记为$WEB_ORACLE_HOME(本例中同$ORACLE_HOME)。 ②Oracle通用安装器自动建立Web服务器别名。安装器编辑文件$WEB_ORACLE_HOME/Apache/jsp/conf/ojsp.conf,依次加入下面三行:
这些行依次为Ultra Search根文档、管理工具和查询应用程序建立Web服务器别名。 ③Oracle通用安装器自动增加产品库、Java查询应用程序接口库和JGL对象库到Java Servlet引擎。安装器编辑文件$WEB_ORACLE_HOME/Apache/Jserv/conf/jserv.properties来包含那些库文件,以下几行将被加入到该文件中:
④通用安装器自动增加目录包含database.properties文件到Servlet引擎库中。安装器编辑文件$WEB_ORACLE_HOME/Apache/Jserv/conf/jserv.properties,下面一行被加入到该文件中:
3、编辑配置文件database.properties,指定JSP应用程序将要连接的数据库的信息。配置文件位于$WEB_ORACLE_HOME/ultrasearch/jsp/admin/config/,用来指定主机名、端口号和SID。为作到这一点,编辑该文件中以"connection.url"开头的行:
在
4、测试Ultra Search管理工具
①首先重新启动Oracle HTTP server。缺省服务器端口号为80,也可在文件$WEB_ORACLE_HOME/Apache/
②浏览 ③用帐号wksys/wksys登录Ultra Search管理工具(第一次访问管理工具时速度可能会很慢,因为要编译JSP文件,接下来的访问会很快)。
④如果成功登录管理工具,那么你已经完成了中间层组件的配置,如果出现登录问题,请按顺序检查下面几项:确保Web服务已经运行;
确保文件database.properties包含Oracle9i服务器实例的正确描述;
确保Oracle9i服务器实例已经运行;
确保Oracle9i服务器实例监听程序运行;
确保Oracle9i服务器实例正确安装Ultra Search服务器组件。
安装过程中,有些文件是系统自动设置的,如果你使用Windows操作系统,还需要把文件路径中的"/"改为"\",因为系统自动以unix路径形式配置这些文件。
登录管理工具后,你需要设置数据库实例、Crawler、Web访问、属性、数据源、Crawler时间进度表、查询数据组和用户。
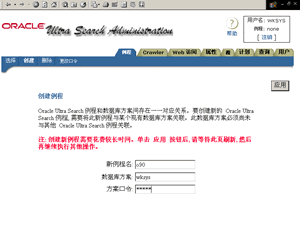
1、首先设置Ultra Search使用的数据库实例,在这个数据库实例中存储所有数据源的索引数据。如图4所示。
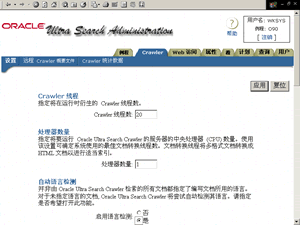
2、然后设置Crawler,如图5所示。
需要设置:处理器数量、自动语言检测、默认语言(该设置很重要,因为语言直接决定了文档的索引方式)、搜索深度(某个Web文档可能包含与其他Web文档的链接,该设置可指定Crawler将跟踪的最大嵌套链接数,即链接层数)、默认字符集、临时目录位置及大小、数据库链接字符串。
● 处理器数量:指定将要运行 Oracle Ultra Search Crawler 的服务器的中央处理器 (CPU) 数量。使用该设置可确定系统使用的最佳文档转换线程数。文档转换线程将多格式文档转换成 HTML 文档以进行适当索引。本例中设置为1。
● 自动语言检测:并非由 Oracle Ultra Search Crawler 检索的所有文档都指定了编写文档所用的语言。对于未指定语言的文档, Oracle Ultra Search Crawler 将尝试自动检测其语言。请指定是否希望打开此功能。本例中设置为"是"。
● 默认语言:如果禁用自动语言检测或者当某个 Web 文档未指定语言时, Crawler 将认为编写该 Web 页的语言是下面指定的默认语言。该设置很重要,因为语言直接决定了文档的索引方式。本例中设置为"简体中文"。
● 搜索深度:某个Web文档可能包含与其他Web文档的链接,从而可能包含更多的链接。使用该设置可指定 Crawler 将跟踪的最大嵌套链接数。本例中设置为3。
● 默认字符集:如果由Crawler处理的某个 HTML 文档没有指定的字符集,该 Crawler 将认为其使用的是下面的默认字符集。本例中设置为"GB2312-80简体中文"
● 临时目录位置及大小:临时目录用于在索引文档过程中进行间断存储。Oracle Ultra Search Crawler 必须能够访问临时目录。请指定临时目录的绝对路径。其大小是 Crawler在索引过程中使用的最大临时空间。指定硬盘中的一个目录即可。
● 数据库连接字符串:数据库连接字符串是 Crawler 需要连接到数据库时使用的标准 JDBC 连接字符串。连接字符串的格式应为: [hostname]:[port]:[SID],本文中是:localhost:1521:o90
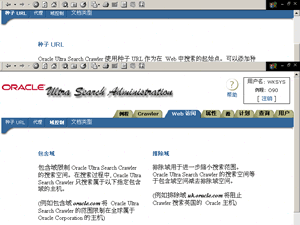
3、设置Web访问,如图6所示。可以指定多个搜索空间,并为搜索空间设定包含域和排除域。搜索过程中,Ultra Search只搜索属于包含域的主机(例如包含域为oracle.com,则搜索范围限制在全球属于Oracle公司的主机),排除域用于进一步缩小搜索范围,搜索空间等于包含域减去排除域(例如排除域为uk.oracle.com将阻止搜索英国的Oracle主机)。
Oracle Ultra Search Crawler 使用种子 URL 作为在 Web 中搜索的起始点。可以添加种子 URL 或从种子 URL 列表中将其删除。Oracle Ultra Search 当前支持使用 HTTP 协议的种子 URL。
注: 如果种子 URL 列表中没有条目, Crawler 不会执行搜索操作。
可以添加一个或多个种子 URL。
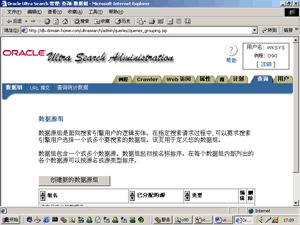
4、指定搜索源。Oracle Ultra Search的强大功能都体现在这个页面中,可以指定Web页面源、文件源、电子邮件源和数据库表源。图7所示为增加文件源到搜索数据源中,可同时指定多个不同种类的数据源。其它数据源请读者自行设定。
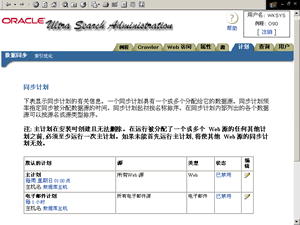
5、设定查询计划。如图8所示。
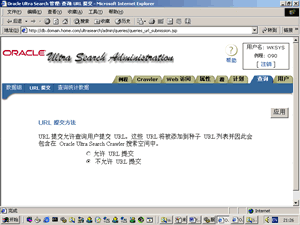
6、设置查询数据组。如图9所示。设置URL提交方式,如图10所示。
URL提交是指是否允许用户使用搜索引擎时提交自己网站的网址。如果浏览过大型搜索引擎网站,有时会发现它允许你把自己网站的网址提交给它,也就是当其他用户浏览这个搜索引擎网站时,他会搜索到你的网站的网页。这里的设置影响用户在搜索查询页面(如图1和图2所示)点击链接"Submit URL"后的效果。你可以让自己的搜索引擎允许其他用户提交URL,你也就成为门户搜索网站了!不过,你的数据库体积可能会爆炸性增长,因为,你的数据库里已经保存了数据源的索引,一般情况来说,这个索引的大小与数据源的大小相当,因此,在为自己的搜索引擎指定数据源时,首先要考虑自己数据库的大小。
查询应用程序位于$WEB_ORACLE_HOME/ultrasearch/sample/jsp目录下,首先在所有jsp文件中找到下面两行:
把它们改为:
否则网页会显示登录错误。
另外,在所有jsp文件中找到字符串"charset=iso-8859-1",更改为"charset=gb2312",否则网页不能正确显示和查询中文字词。
这里的用户名和密码为数据库安装Ultra Search组件时自动建立。
然后浏览 特性:
较高的搜索结果相关度;
完全和数据库服务器、SQL查询语言集成,更好地与动态数据交互作用;
带有业界优秀的语言学技术;
带有类似概念搜索、主题分析和XML搜索能力的高级特性;
索引所有流行的150多种文件格式;
以Web形式搜索文件服务器;
完美的全球化支持,包括支持中文、日文、朝鲜语和统一字符编码标准。
Ultra Search的使用体会:
易于安装、易于管理,可以在不到一天的时间安装调试完成,普通用户最好能得到数据库管理员(DBA)的帮助;
它是一项前台技术,不要求使用者有任何应用程序开发的能力;
高性能、可扩展,提供二次开发平台,你可以轻松改动JSP程序,比如去掉图1和图2中的Oracle产品标志,去掉搜索结果相关度分值等。
局限:
搜索Web源的网址中不能含注册字符串;
只能在一个数据库中建立Ultra Search数据库实例,除非你编辑文件database.properties,每次切换到不同的数据库,因为索引数据量会越来越大;
不容易调整Ultra Search数据库对象的存储参数;
Ultra Search暂时没有在索引数据中存储数据源快照(副本)的功能。
|