MySQL中distinct与group by之间的性能进行比较 |
|
最近在网上看到了一些测试,感觉不是很准确,今天亲自测试了一番 。得出了结论,测试过程在个人计算机上,可能不够全面,仅供参考 。 测试过程: CREATE TABLE `test_test` ( `id` int(11) NOT NULL auto_increment, `num` int(11) NOT NULL default 0, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; 建个储存过程向表中插入10W条数据
create procedure p_test(pa int(11))
begin
declare max_num int(11) default 100000;
declare i int default 0;
declare rand_num int;
select count(id) into max_num from test_test;
while i < pa do
if max_num < 100000 then
select cast(rand()*100 as unsigned) into rand_num;
insert into test_test(num)values(rand_num);
end if;
set i = i +1;
end while;
end
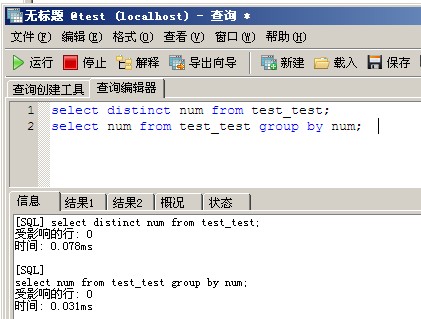
调用存储过程插入数据 call p_test(100000); 开始测试:(不加索引) select distinct num from test_test; select num from test_test group by num; [SQL] select distinct num from test_test; 受影响的行: 0 时间: 0.078ms [SQL] select num from test_test group by num; 受影响的行: 0 时间: 0.031ms
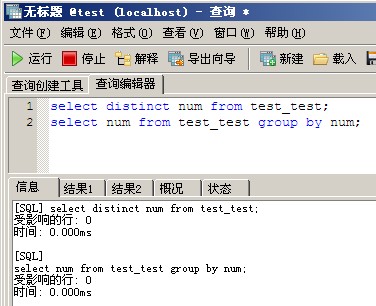
二、num字段上创建索引 ALTER TABLE `test_test` ADD INDEX `num_index` (`num`) ; 再次查询 select distinct num from test_test; select num from test_test group by num; [SQL] select distinct num from test_test; 受影响的行: 0 时间: 0.000ms [SQL] select num from test_test group by num; 受影响的行: 0 时间: 0.000ms
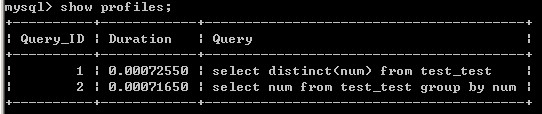
这时候我们发现时间太小了 0.000秒都无法精确了 。 mysql> set profiling=1; mysql> select distinct(num) from test_test; mysql> select num from test_test group by num; mysql> show profiles; +----------+------------+----------------------------------------+ | Query_ID | Duration | Query | +----------+------------+----------------------------------------+ | 1 | 0.00072550 | select distinct(num) from test_test | | 2 | 0.00071650 | select num from test_test group by num | +----------+------------+----------------------------------------+
分析: 因此使用的时候建议选 group by 。 以上就是在MySQL中distinct与group by之间的性能进行比较的,通过以上比较是不是对distinct和group by有了更深入的了解,希望对大家的学习有所帮助 。 |