详解MySql基本查询、连接查询、子查询、正则表达查询 |
|
查询数据指从数据库中获取所需要的数据 。查询数据是数据库操作中最常用,也是最重要的操作 。用户可以根据自己对数据的需求,使用不同的查询方式 。通过不同的查询方式,可以获得不同的数据 。MySQL中是使用SELECT语句来查询数据的 。在这一章中将讲解的内容包括 。 1、查询语句的基本语法 什么是查询?
怎么查的?
数据的准备如下: create table STUDENT( STU_ID int primary KEY, STU_NAME char(10) not null, STU_AGE smallint unsigned not null, STU_SEX char(2) not null ); insert into STUDENT values(2001,小王,13,男); insert into STUDENT values(2002,明明,12,男); insert into STUDENT values(2003,红红,14,女); insert into STUDENT values(2004,小花,13,女); insert into STUDENT values(2005,天儿,15,男); insert into STUDENT values(2006,阿猎,13,女); insert into STUDENT values(2007,阿猫,16,男); insert into STUDENT values(2008,阿狗,17,男); insert into STUDENT values(2009,黑子,14,男); insert into STUDENT values(2010,小玉,13,女); insert into STUDENT values(2011,头头,13,女); insert into STUDENT values(2012,冰冰,14,女); insert into STUDENT values(2013,美丽,13,女); insert into STUDENT values(2014,神乐,12,男); insert into STUDENT values(2015,天五,13,男); insert into STUDENT values(2016,小三,11,男); insert into STUDENT values(2017,阿张,13,男); insert into STUDENT values(2018,阿杰,13,男); insert into STUDENT values(2019,阿宝,13,女); insert into STUDENT values(2020,大王,14,男); 然后这是学生成绩表,其中定义了外键约束 create table GRADE( STU_ID INT NOT NULL, STU_SCORE INT, foreign key(STU_ID) references STUDENT(STU_ID) ); insert into GRADE values(2001,90); insert into GRADE values(2002,89); insert into GRADE values(2003,67); insert into GRADE values(2004,78); insert into GRADE values(2005,89); insert into GRADE values(2006,78); insert into GRADE values(2007,99); insert into GRADE values(2008,87); insert into GRADE values(2009,70); insert into GRADE values(2010,71); insert into GRADE values(2011,56); insert into GRADE values(2012,85); insert into GRADE values(2013,65); insert into GRADE values(2014,66); insert into GRADE values(2015,77); insert into GRADE values(2016,79); insert into GRADE values(2017,82); insert into GRADE values(2018,88); insert into GRADE values(2019,NULL); insert into GRADE values(2020,NULL); 一、查询语句的基本语法 查询数据是指从数据库中的数据表或视图中获取所需要的数据,在MySQL中,可以使用SELECT语句来查询数据 。根据查询条件的不同,数据库系统会找到不同的数据 。 SELECT 属性列表 FROM 表名或视图列表 [WHERE 条件表达式1] [GROUP BY 属性名1 [HAVING 条件表达式2]] [ORDER BY 属性名2 [ASC|DESC]] 属性列表:表示需要查询的字段名 。 如果有WHERE子句,就按照“条件表达式1”指定的条件进行查询;如果没有WHERE子句,就查询所有记录 。 二、在单表上查询数据 2.1、查询所有字段 复制代码 代码如下: select * from STUDENT;
2.2、按条件查询
(1) 比较运算符 select * from STUDENT where STU_AGE>13;
in(v1,v2..vn) ,符合v1,v2,,,vn才能被查出 select * from STUDENT where STU_AGE in(11,12);
between v1 and v2 在v1至v2之间(包含v1,v2) select * from STUDENT where STU_AGE between 13 and 15;
(2)逻辑运算符 not ( ! ) 逻辑非 select * from STUDENT where STU_AGE NOT IN(13,14,16);
or ( || ) 逻辑或 select * from STUDENT where STU_ID<2005 OR STU_ID>2015;
and ( && ) 逻辑与 (3)模糊查询 like 像 LIKE关键字可以匹配字符串是否相等 。如果字段的值与指定的字符串相匹配,则满足查询条件,该纪录将被查询出来 。如果与指定的字符串不匹配,则不满足查询条件 。其语法规则如下:[ NOT ] LIKE 字符串 “NOT”可选参数,加上 NOT表示与指定的字符串不匹配时满足条件;“字符串”表示指定用来匹配的字符串,该字符串必须加单引号或双引号 。 通配符: % 任意字符 select * from STUDENT where STU_NAME LIKE %王; 表示匹配任何以王结尾的
select * from STUDENT where STU_NAME LIKE 阿%; 表示匹配任何以阿开头的
_ 单个字符 比如说插入 select * from STUDENT where STU_NAME LIKE 阿%; 然后 select * from STUDENT where STU_NAME LIKE 阿%; 查询的结果为空
但是如果下后面加两个_符号 select * from STUDENT where STU_NAME LIKE _下__; 查询结果不为空
“字符串”参数的值可以是一个完整的字符串,也可以是包含百分号(%)或者下划线(_)的通配字符 。二者有很大区别 (4)空值查询 IS NULL关键字可以用来判断字段的值是否为空值(NULL) 。如果字段的值是空值,则满足查询条件,该记录将被查询出来 。如果字段的值不是空值,则不满足查询条件 。其语法规则如下: 三、使用聚合函数查询数据 3.1、group by 分组 select * from STUDENT group by STU_SEX; 不加条件,那么就只取每个分组的第一条 。
如果想看分组的内容,可以加groub_concat select STU_SEX,group_concat(STU_NAME) from STUDENT group by STU_SEX;
3.2、一般情况下group需与统计函数(聚合函数)一起使用才有意义 create table EMPLOYEES( EMP_NAME CHAR(10) NOT NULL, EMP_SALARY INT unsigned NOT NULL, EMP_DEP CHAR(10) NOT NULL ); insert into EMPLOYEES values(小王,5000,销售部); insert into EMPLOYEES values(阿小王,6000,销售部); insert into EMPLOYEES values(工是不,7000,销售部); insert into EMPLOYEES values(人人乐,3000,资源部); insert into EMPLOYEES values(满头大,4000,资源部); insert into EMPLOYEES values(天生一家,5500,资源部); insert into EMPLOYEES values(小花,14500,资源部); insert into EMPLOYEES values(大玉,15000,研发部); insert into EMPLOYEES values(条条,12000,研发部); insert into EMPLOYEES values(笨笨,13000,研发部); insert into EMPLOYEES values(我是天才,15000,研发部); insert into EMPLOYEES values(无语了,6000,审计部); insert into EMPLOYEES values(什么人,5000,审计部); insert into EMPLOYEES values(不知道,4000,审计部); mysql中的五种统计函数: select EMP_NAME,EMP_DEP,max(EMP_SALARY) from EMPLOYEES group by EMP_DEP;
(2)min:求最小值 select EMP_NAME,EMP_DEP,min(EMP_SALARY) from EMPLOYEES group by EMP_DEP;
(3)sum:求总数和 select EMP_DEP,sum(EMP_SALARY) from EMPLOYEES group by EMP_DEP
(4)avg:求平均值 select EMP_DEP,avg(EMP_SALARY) from EMPLOYEES group by EMP_DEP;
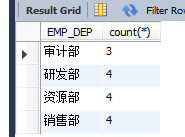
(5)count:求总行数 select EMP_DEP,count(*) from EMPLOYEES where EMP_SALARY>=500 group by EMP_DEP;
3.3、带条件的groub by 字段 having,利用HAVING语句过滤分组数据 复制代码 代码如下: select EMP_DEP,avg(EMP_SALARY),group_concat(EMP_NAME)from EMPLOYEES group by EMP_DEP HAVING avg(EMP_SALARY) >=6000;
查找平均工资大于6000的部门,并把部门里的人全部列出来
四、多表上联合查询 复制代码 代码如下: select STUDENT.STU_ID,STUDENT.STU_NAME,STUDENT.STU_AGE,STUDENT.STU_SEX,GRADE.STU_SCORE from STUDENT,GRADE WHERE STUDENT.STU_ID=GRADE.STU_ID AND GRADE.STU_SCORE >=90;
查找大于90分的学生信息:
(2)显式内连接查询 复制代码 代码如下: select STUDENT.STU_ID,STUDENT.STU_NAME,STUDENT.STU_AGE,STUDENT.STU_SEX,GRADE.STU_SCORE from STUDENT inner join GRADE on STUDENT.STU_ID=GRADE.STU_ID AND GRADE.STU_SCORE >=90;
用法:select .... from 表1 inner join 表2 on 条件表达式 (3)外连接查询 复制代码 代码如下: select STUDENT.STU_ID,STUDENT.STU_NAME,STUDENT.STU_AGE,STUDENT.STU_SEX,GRADE.STU_SCORE from STUDENT left join GRADE on STUDENT.STU_ID=GRADE.STU_ID;
right join就是相反的了,用法相同 五、子查询 select * from STUDENT where STU_ID IN(select STU_ID from GRADE where STU_SCORE>85); 查找大于85分的学生信息
2、与EXISTS结合 select * from STUDENT where EXISTS (select STU_ID from GRADE where STU_SCORE>=100); 如果有学生成绩大于100,才查询所有的学生信息
3、ALL、ANY和SOME子查询 select STU_ID from GRADE where STU_SCORE <67;
只要学号大于上面的任意一个就显示出来: 复制代码 代码如下: select * from STUDENT where STU_ID >= any (select STU_ID from GRADE where STU_SCORE <67);
六、合并查询结果 SELECT语句1 UNION | UNION ALL SELECT语句2 UNION | UNION ALL …. SELECT语句n ; 七、排序与取数 select * from GRADE where STU_SCORE >80 order by STU_SCORE; 默认是按升序的, select * from GRADE where STU_SCORE >80 order by STU_SCORE ASC; 结果如下:
如果想换成降序的: select * from GRADE where STU_SCORE >80 order by STU_SCORE desc;
7.2、limit limit [offset,] N select * from GRADE order by STU_SCORE desc limit 5;
取分数最低的前5条 select * from GRADE order by STU_SCORE asc limit 5;
取分数排名在10-15之间的5条 select * from GRADE order by STU_SCORE desc limit 10,5
八、为表和字段取别名 使用AS来命名列 select STU_ID as 学号,STU_SCORE as 分数 from GRADE;
当表的名称特别长时,在查询中直接使用表名很不方便 。这时可以为表取一个别名 。用这个别名来代替表的名称 。 复制代码 代码如下: select S.STU_ID,S.STU_NAME,S.STU_AGE,S.STU_SEX,G.STU_SCORE from STUDENT S,GRADE G WHERE S.STU_ID=G.STU_ID AND G.STU_SCORE >=90;
九、使用正则表达式查询 正则表达式是用某种模式去匹配一类字符串的一个方式 。例如,使用正则表达式可以查询出包含A、B、C其中任一字母的字符串 。正则表达式的查询能力比通配字符的查询能力更强大,而且更加的灵活 。正则表达式可以应用于非常复杂查询 。
在使用前先插入一些数据: insert into STUDENT values(2022,12wef,13,男); insert into STUDENT values(2023,faf_23,13,男); insert into STUDENT values(2024,fafa,13,女); insert into STUDENT values(2025,ooop,14,男); insert into STUDENT values(2026,23oop,14,男); insert into STUDENT values(2027,woop89,14,男); insert into STUDENT values(2028,abcdd,11,男); (1)使用字符“^”可以匹配以特定字符或字符串开头的记录 。 select * from STUDENT where STU_NAME REGEXP ^阿;
以数字开头 select * from STUDENT where STU_NAME REGEXP ^[0-9]; (2)使用字符“$”可以匹配以特定字符或字符串结尾的记录 select * from STUDENT where STU_NAME REGEXP [0-9]$;
(3)用正则表达式来查询时,可以用“.”来替代字符串中的任意一个字符 。 select * from STUDENT where STU_NAME REGEXP ^w....[0-9]$; 以w开头,以数字结束,中间有4个
(4)使用方括号([]) 可以将需要查询字符组成一个字符集 。只要记录中包含方括号中的任意字符,该记录将会被查询出来 。 使用方括号可以指定集合的区间 。
使用“[^字符集合]”可以匹配指定字符以外的字符 (5){}表示出现的次数 正则表达式中,“字符串{M}”表示字符串连续出现M次;“字符串{M,N}”表示字符串联连续出现至少M次,最多N次 。例如,“ab{2}”表示字符串“ab”连续出现两次 。“ab{2,4}”表示字符串“ab”连续出现至少两次,最多四次 。
select * from STUDENT where STU_NAME REGEXP o{2};
(6)+表示到少出现一次 select * from STUDENT where STU_NAME REGEXP (fa)+;
注意: 以上所述就是本文的全部内容,希望大家能够喜欢 。 |