MySQL性能优化 出题业务SQL优化 |
|
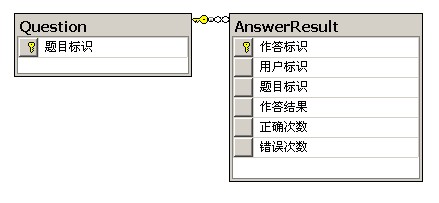
本文标签:MySQL,性能优化 先简单介绍一下项目背景 。这是一个在线考试练习平台,数据库使用MySQL,表结构如图所示:
Question是存储题目的表,数据量在3万左右 。AnswerResult表是存储用户作答结果的表,分表之后单表记录大概在300万-400万 。 需求:根据用户的作答结果出练习卷,题目的优先级为:未做过的题目>只做错的题目>做错又做对的题目>只做对的题目 。 在“做错又做对的题目”中,会按错误次数和正确次数的比例进行权重计算,比如:A、做错10次,做对100次;B、做错10次,做对20次 。这时B被选中出给用户练习的概率就大 。 备注:AnswerResult表中不存在QuestionId的记录,则代表该题没有做过 。 之前使用的方法: SELECT Question.题目标识,IFNULL((0-正确次数)/(正确次数+错误次数),1) AS 权重 FROM Question LEFT JOIN AnswerResult ON AnswerResult.题目标识 = Question.题目标识 WHERE 用户标识={UserId} 说明:IFNULL((0-正确次数)/(正确次数+错误次数),1)这个函数式分2部分, 公式:(0-正确次数)/(正确次数+错误次数)得到题目的权重,这个区间为[0,-1],0表示只做错的题目,-1表示只做对的题目 。IFNULL(value,1)则将未做过的题目权重设置为1,根据这个权重进行排序列出题目 。 由于AnswerResult表是多达300、400百万的表,所以通过LEFT JOIN进行左连接时,迪卡尔乘积过大,又加上AnswerResult是频繁读写的表,很容易导致这条SQL变成慢查询 。 性能问题被提上日程后,这条SQL语句就变成的优化点 。 1、IFNULL()这个函数计算可以调整成冗余字段 。 2、LEFT JOIN的迪卡尔乘积太大,可以调整为冗余或者使用INNER JOIN以提高查询速度 。 3、根据需求,其实可以调整出题策略,不同的情况执行不同的SQL,而不需要在同一条SQL中实现 。 解决方案针对以上三个点进行调整 。虽然Question表有3万条数据,但是出题的场景其实是针对知识点出题,单个知识点题目最多也只有1000题左右,所以获取未做过的题目时,完全可以使用NOT IN走索引来完成 。SQL语句如: A:SELECT 题目标识 FROM Question WHERE 知识点={KnowledgePointCode} AND 题目标识 NOT IN ( SELECT 题目标识 FROM AnswerResult INNER JOIN Question AND Question.知识点={KnowledgePointCode} WHERE AnswerResult.用户标识 = {UserId} ) 针对只做错的题目出题练习就简单了(正确次数 = 0代表只做错),SQL如: B:SELECT 题目标识 FROM AnswerResult INNER JOIN Question AND Question.知识点={KnowledgePointCode} WHERE AnswerResult.用户标识 = {UserId} AND 正确次数 = 0 ORDER BY 错误次数 DESC 若要对做错、做对或者只做对的题目进行出题,SQL就是这样的(已经对权重进行冗余=IFNULL((0-正确次数)/(正确次数+错误次数),1)): C:SELECT 题目标识 FROM AnswerResult INNER JOIN Question AND Question.知识点={KnowledgePointCode} WHERE AnswerResult.用户标识 = {UserId} AND 正确次数 > 0 ORDER BY 权重 DESC
不足:SQL语句A的查询速度依然是较慢的,虽然有缩小NOT IN的结果集,但这里还是有优化点 。园子里的朋友们能不能给点建议? 有人说JOIN是SQL的性能杀手,我觉得主要还是怎么去使用JOIN,MySQL的索引优化相当重要,如果JOIN成为性能瓶颈,可以EXPLAIN看看是不是索引没有建好,并且尽量让迪卡尔乘积尽量小 。使用冗余数据避免JOIN,当可能变化的冗余数据被分表之后,更新这些冗余数据就是一件非常头痛的事了 。海量数据高并发,确实是一件挺头痛的事 。 望园子里有这方面经验的朋友不吝赐教 。谢谢 。 |