NodeJS的url截取模块url-extract的使用实例 |
|
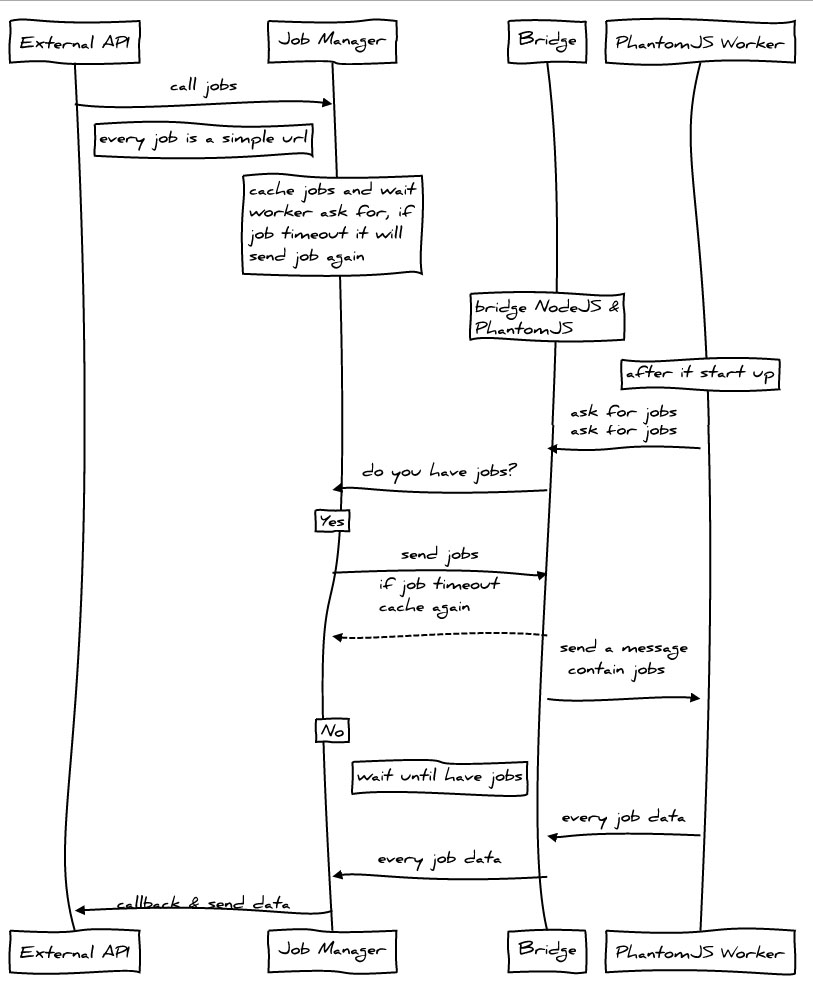
本文标签:url截取 上次介绍了怎么利用NodeJS + PhantomJS进行截图,但由于对每次截图操作,都启用了一个PhantomJS进程,所以并发量上去后,效率堪忧,所以我们重写了所有代码,并将其独立成为一个模块,方便调用 。
依赖 & 安装 由于PhantomJS 1.9.0+才开始支持Websocket,所以我们先要确定在PATH中的PhantomJS是为1.9.0以上版本 。在命令行键入:
如果能返回版本号1.9.x,则可以继续操作 。如果版本过低,或者出现错误,请到PhantomJS官网下载最新版本 。 如果你已经安装了Git,或者拥有Git Shell,那么在命令行键入: 进行安装 。 复制代码 代码如下: module.exports = (function () { "use strict" var urlExtract = require(url-extract); urlExtract.snapshot(http://www.baidu.com, function (job) { console.log(This is a snapshot example.); console.log(job); process.exit(); }); })();
下面是打印:
其中,image属性就是截图相对于工作路径的地址 。我们可以使用Job的getData接口来得到更清楚的数据,例如: 复制代码 代码如下: module.exports = (function () { "use strict" var urlExtract = require(url-extract); urlExtract.snapshot(http://www.baidu.com, function (job) { console.log(This is a snapshot example.); console.log(job.getData()); process.exit(); }); })();
打印就变成了这样了:
image表示截图相对于工作路径的地址,status表示状态是否正常,true代表正常,false代表截图失败 。 更多例子请参见:https://github.com/miniflycn/url-extract/tree/master/examples 主要API .snapshot url快照 .snapshot(url, [callback]).snapshot(urls, [callback]).snapshot(url, [option]).snapshot(urls, [option])
|