ШэМўПЊЗЂХрбЕАр >> БрГЬПЊЗЂ >> JavaScript
ШэМўПЊЗЂХрбЕАр >> БрГЬПЊЗЂ >> JavaScript
ДгЪ§ОнНсЙЙЕФНЧЖШЗжЮі for each in БШ for in ПьЕФЖр |
|
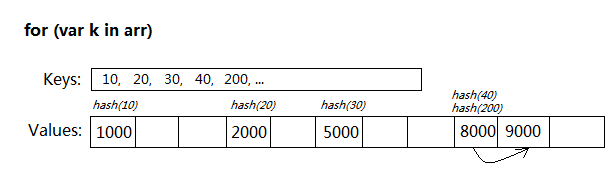
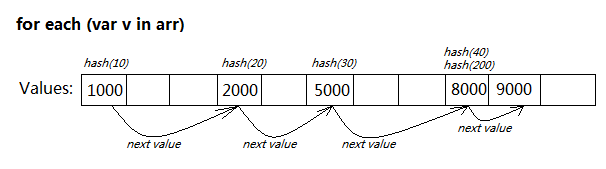
ЁЁЁЁБОЮФБъЧЉЃКfor,each жЎЧАЬ§ЫЕЛ№КќЕФJSв§ЧцжЇГжfor each inЕФгяЗЈЃЌР§ШчЯТЪіЕФДњТыЃК ИДжЦДњТы ДњТыШчЯТ: var arr = [10,20,30,40,50]; for each(var k in arr) console.log(k); ЁЁЁЁМДПЩжБНгБщРњГіarrЪ§зщЕФФкШн ЁЃ ЁЁЁЁгЩгкжЛгаFireFoxВХжЇГжЃЌЫљвдМИКѕЫљгаЕФJSДњТыЖМВЛгУетвЛЬиеї ЁЃ ЁЁЁЁВЛЙ§дкActionScriptРяЬьЩњОЭжЇГжfor eachЕФгяЗЈЃЌВЛТлArrayЛЙЪЧVectorЃЌЛЙЪЧDictionaryЃЌжЛвЊЪЧПЩУЖОйЕФЖдЯѓЖМПЩвдfor inКЭfor each in ЁЃ ЁЁЁЁжЎЧАВЂУЛгаИаОѕгаЬЋДѓЕФВювьЃЌЮЊСЫРСЕУЧУвЛИіeachЕЅДЪЃЌвЛжБгУЪьЯЄЕФfor inРДБщРњ ЁЃ ЁЁЁЁВЛЙ§НёЬьзаЯИзСФЅСЫЛсЃЌДгЪ§ОнНсЙЙЕФНЧЖШЗжЮіСЫЯТЃЌОѕЕУfor inКЭfor each inаЇТЪЩЯгазХБОжЪЕФЧјБ№ЃЌЮоТлЪЧJSЛЙЪЧAS ЁЃ ЁЁЁЁдвђКмМђЕЅЃКArrayВЛЪЧеце§втвхЩЯЕФЪ§зщЃЁ ЁЁЁЁКЮЮЊеце§втвхЕФЪ§зщЃПЕБШЛОЭЪЧДЋЭГгябдРяtype[]ЖЈвхЕФЪ§ОнРраЭЃЌЫљгадЊЫиЖМЪЧСЌајБЃДцЕФ ЁЃ ЁЁЁЁЁАArrayЁБЫфШЛвВЪЧЪ§зщЕФвтЫМЃЌЕЋЪьЯЄJSЕФЖМжЊЕРЃЌЫќЦфЪЕЪЧИіЗЧЯпадЕФЮБЪ§зщЃЌЯТБъПЩвдЪЧШЮвтЪ§зж ЁЃаДШыarr[1000000]ВЂЗЧеце§ЩъЧыШнФЩвЛАйЭђИідЊЫиЕФПеМфЃЌЖјЪЧАб1000000зЊЛЛГЩЯргІЕФЙўЯЃжЕЃЌЖдгІЕНКмаЁвЛПщДЂДцПеМфРяЃЌДгЖјНкЪЁСЫДѓСПФкДц ЁЃ ИДжЦДњТы ДњТыШчЯТ: var arr = []; arr[10] = 1000; arr[20] = 2000; arr[30] = 5000; arr[40] = 8000; arr[200] = 9000; гУfor...inБщРњArrayЃЌЪЧИіКмРлзИЕФЙ§ГЬЃК
БщРњЪБУПДЮЗУЮЪarr[k]ЃЌЖМвЊНјаавЛДЮHash(k)МЦЫуЃЌИљОнЩЂСаБэЕФШнСПШЁФЃЃЌШчЙћДцдкГхЭЛЛЙЕУбАевзюжеЕФжЕНсЙћ ЁЃ
ArrayРяжБНгАбУПИіvaluesзїЮЊНкЕуЃЌЭЈЙ§СДБэЙиСЊЦ№РДЮЌЛЄ ЁЃУПЕБгажЕЬэМгЛђЩОГ§ЃЌОЭИќаТЦфСДНгЙиЯЕ ЁЃ |